
机器学习期末作业,依据K-means算法的社区用户聚类剖析
当然能够!机器学习期末作业的难度和内容取决于你的课程进展和教师的要求。一般,这类作业或许包含以下几个方面:
1. 理论知识的温习与运用:回忆学过的机器学习算法,如线性回归、决策树、支撑向量机、神经网络等,并了解它们的原理和适用场景。
2. 数据处理与剖析:学习怎么搜集、清洗、预处理和可视化数据,为后续的机器学习模型练习做准备。
3. 模型练习与评价:挑选适宜的算法,运用练习数据集进行模型练习,并对模型进行评价,如核算准确率、召回率、F1分数等方针。
4. 模型优化与调参:依据评价成果,对模型进行优化,调整参数,以进步模型的功能。
5. 实践运用事例:测验将机器学习运用于实践问题,如图像识别、文本分类、引荐体系等,并剖析其作用。
6. 编程完结:运用Python等编程言语完结机器学习算法,并编写代码进行模型练习和评价。
8. 团队协作与沟通:假如作业是团队项目,还需求学习怎么与团队成员有用沟通、分工协作,一起完结任务。
9. 学术标准与品德:了解学术标准,防止抄袭、剽窃等行为,保证作业的原创性。
10. 时刻管理:合理组织时刻,保证在截止日期前完结作业。
1. 仔细阅读作业要求,保证了解教师的希望和评分标准。
2. 拟定详细的学习方案,包含每天的学习内容和时刻组织。
3. 参阅教材、讲义、课程笔记等学习材料,稳固理论知识。
4. 运用在线资源,如Coursera、edX等平台上的机器学习课程,拓展知识面。
5. 参加讨论区,与同学和教师沟通学习心得,处理疑问。
6. 编写代码时,留意代码的可读性和标准性,运用注释和文档阐明。
7. 定时备份作业,以防数据丢掉。
8. 在截止日期前提交作业,防止延迟。
祝你顺利完结机器学习期末作业!
机器学习期末作业:依据K-means算法的社区用户聚类剖析
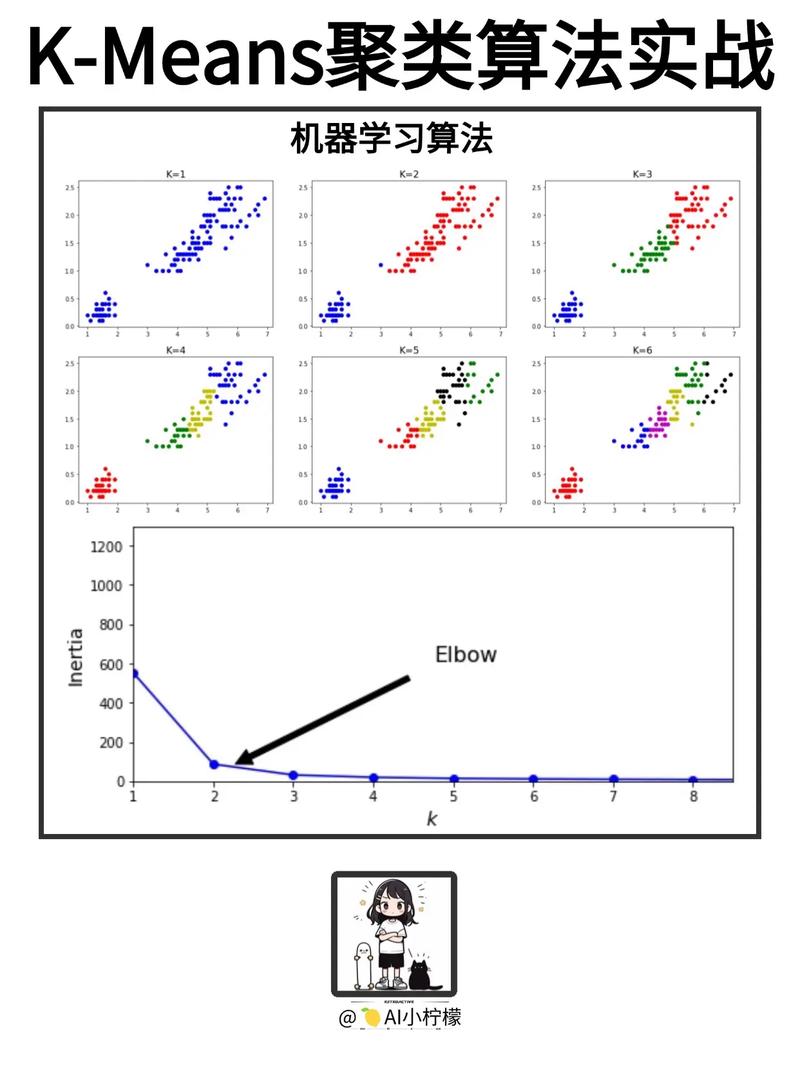
社区用户聚类剖析是机器学习范畴的一个重要研讨方向。经过对社区用户进行聚类,能够协助咱们更好地了解用户集体的特征,为社区运营、精准营销等供给数据支撑。K-means算法是一种常用的聚类算法,具有简略、高效的特色,适用于处理大规模数据集。
二、数据预处理
在进行聚类剖析之前,需求对原始数据进行预处理,包含数据清洗、特征挑选和标准化等进程。
2.1 数据清洗
数据清洗是数据预处理的第一步,首要意图是去除数据中的噪声和异常值。在本研讨中,咱们选用以下办法进行数据清洗:
去除重复数据:经过比较数据会集的记载,去除重复的用户信息。
处理缺失值:关于缺失的数据,选用均值、中位数或众数等办法进行填充。
去除异常值:经过剖析数据散布,去除显着违背正常规模的异常值。
2.2 特征挑选
特征挑选是挑选对聚类成果影响较大的特征,以进步聚类作用。在本研讨中,咱们选用以下办法进行特征挑选:
信息增益:依据特征的信息增益,挑选对聚类成果影响较大的特征。
卡方查验:依据特征与方针变量之间的相关性,挑选对聚类成果影响较大的特征。
2.3 数据标准化
数据标准化是将不同量纲的特征转换为相同量纲的进程,以消除特征之间的量纲影响。在本研讨中,咱们选用Z-score标准化办法进行数据标准化。
三、K-means算法聚类剖析
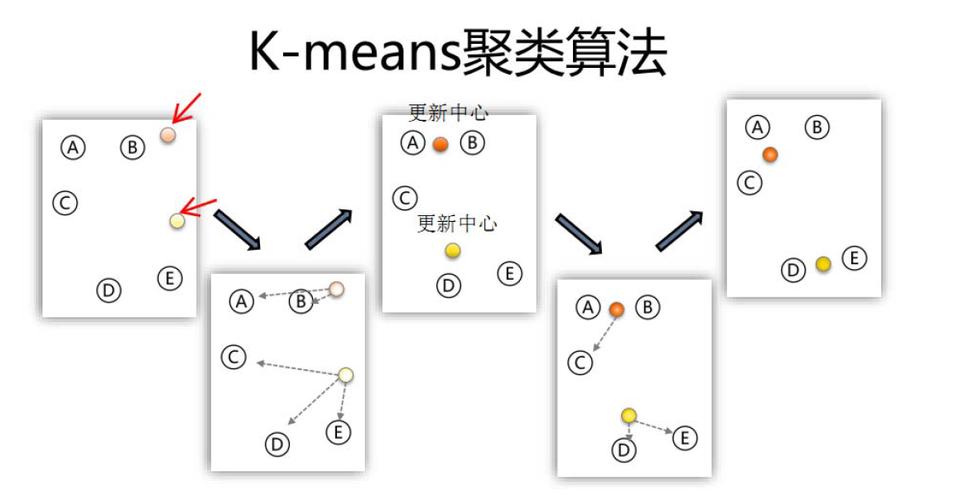
在完结数据预处理后,咱们能够运用K-means算法对社区用户进行聚类剖析。
3.1 初始化聚类中心
首要,咱们需求随机挑选K个用户作为初始聚类中心。
3.2 核算间隔并分配簇
关于每个用户,核算其与K个聚类中心的间隔,并将其分配到间隔最近的聚类中心地点的簇。
3.3 更新聚类中心
依据每个簇中的用户,从头核算聚类中心,并重复进程3.2和3.3,直到聚类中心不再发生变化或到达预设的迭代次数。
四、成果剖析

经过K-means算法对社区用户进行聚类剖析后,咱们能够得到以下成果:
4.1 聚类成果可视化
运用散点图或热力求等可视化办法,展现聚类成果,以便直观地了解用户集体的散布状况。
4.2 聚类特征剖析
剖析每个簇的特征,了解不同用户集体的特征差异,为社区运营和精准营销供给数据支撑。
五、定论

本文依据K-means算法,对社区用户进行聚类剖析,并探讨了聚类成果在实践运用中的价值。经过聚类剖析,咱们能够更好地了解用户集体的特征,为社区运营、精准营销等供给数据支撑。在实践运用中,能够依据详细需求调整聚类算法和参数,以进步聚类作用。
相关
-
百变机器学习,探究人工智能的无限或许详细阅读

“百变机器学习”实际上是指《百面机器学习》这本书。该书由诸葛越编写,首要涵盖了机器学习范畴的多个方面,旨在协助读者构建一个全面的机器学习常识体系。书中具体介绍了特征工程、模型评...
2024-12-26 2
-
神经网络与机器学习,探究智能年代的核心技能详细阅读

神经网络和机器学习是两个密切相关但有所区别的概念。神经网络是一种仿照人脑作业原理的核算模型,由很多彼此衔接的神经元组成。每个神经元接纳输入信号,经过激活函数处理这些信号,然后输...
2024-12-26 2
-
机器学习吴恩达笔记,浅显易懂吴恩达机器学习笔记——敞开AI学习之旅详细阅读

1.知乎专栏:2.CSDN博客:3.GitHub资源:这些资源涵盖了吴恩达机器学习课程的各个章节,包含线性...
2024-12-26 2
-
形式辨认与机器学习,技能交融与未来展望详细阅读

形式辨认与机器学习是两个严密相关但又有差异的范畴。它们都是人工智能的子范畴,致力于让计算机可以从数据中学习并做出决议计划。形式辨认首要重视怎么自动辨认和分类数据中的形式。它一般...
2024-12-26 2
-
机器学习 mobi详细阅读

基本概念机器学习是一门多范畴交叉学科,触及概率论、统计学、迫临论、算法杂乱度理论等多门学科。其主要研讨核算机怎么模仿或完成人类的学习行为,以获取新的常识或技能,重新组织已有的...
2024-12-26 2
-
ai归纳点评办法,全面解析与未来展望详细阅读

1.精确性点评:经过比较AI体系或模型的输出与实在值或专家判别,来点评其精确性。这一般涉及到核算各种目标,如精确率、召回率、F1分数等。2.稳定性点评:点评AI体系或模型在...
2024-12-26 3
-
48ai归纳,探究人工智能在各个范畴的使用与应战详细阅读

PreSonusStudioLive48AIMixSystem是一款功用强壮的48通道数字调音台体系,适用于各种现场表演和专业录音环境。以下是该体系的具体特色:1....
2024-12-26 4
-
机器人课程学习,敞开未来科技之旅详细阅读

机器人课程学习指南1.了解机器人根底常识:机器人分类:了解不同类型的机器人,例如工业机器人、服务机器人、特种机器人等,以及它们的运用范畴。机器人结构:学...
2024-12-26 3
-
ai软件,技能革新与职业运用详细阅读

1.归纳类AI东西:百度文心一言:百度推出的依据文心大模型的AI对话产品,支撑对话互动、问题答复和创造帮忙。阿里通义千问:背靠阿里云强壮的核算才能和数据资源,...
2024-12-26 4
-
ai归纳数据,驱动未来智能开展的中心动力详细阅读

关于AI归纳数据,以下是几份具体的陈述和研讨,供您参阅:1.2024年我国AI根底数据服务研讨陈述:该陈述由我国信息通讯研讨院发布,具体剖析了我国AI根底数据服务商场的...
2024-12-26 2