
大数据分布式核算,大数据分布式核算概述
大数据分布式核算是一种核算办法,用于处理大规模数据集。它经过将数据涣散到多个核算节点上,完成并行核算,以进步核算速度和功率。这种办法在处理大数据时非常重要,由于它能够处理单台核算机无法处理的问题。
大数据分布式核算一般触及以下几个关键步骤:
1. 数据切割:将大数据集切割成多个小块,以便在多个核算节点上并行处理。
2. 数据分发:将数据块分发到各个核算节点上。
3. 并行核算:在每个核算节点上独立地处理数据块,并生成中心成果。
4. 成果兼并:将各个核算节点的中心成果兼并成终究成果。
5. 成果存储:将终究成果存储在存储体系中,以便进行后续剖析和处理。
大数据分布式核算能够选用多种技能完成,如MapReduce、Spark、Hadoop等。这些技能都供给了对大数据进行分布式核算的支撑,但它们的完成办法和功能特色各不相同。
在大数据分布式核算中,还需要考虑数据共同性和容错性等问题。数据共同性是指确保各个核算节点上的数据是共同的,而容错性是指当某个核算节点呈现毛病时,体系能够主动从其他节点上康复数据,并继续进行核算。
总归,大数据分布式核算是一种处理大规模数据集的有用办法,它经过将数据涣散到多个核算节点上,完成并行核算,以进步核算速度和功率。
大数据分布式核算概述
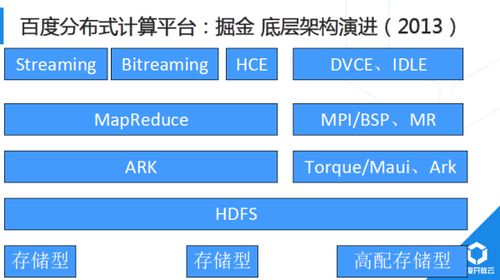
大数据分布式核算的优势

1. 高效处理海量数据:分布式核算能够将数据涣散存储在多个节点上,并行处理,然后进步数据处理功率,满意海量数据的处理需求。
2. 高可靠性:分布式核算结构具有容错机制,当某个节点产生毛病时,其他节点能够接收其使命,确保体系的高可靠性。
3. 高扩展性:分布式核算结构能够依据需求动态调整节点数量,完成体系的水平扩展,满意不断添加的数据处理需求。
4. 资源利用率高:分布式核算结构能够充分利用集群中的核算资源,进步资源利用率。
大数据分布式核算结构

1. Hadoop:Hadoop是一个开源的大数据处理结构,包含HDFS(分布式文件体系)和MapReduce(分布式核算结构)。Hadoop具有高可靠性、高扩展性、高效性等特色,适用于大规模数据集的存储和处理。
2. Spark:Spark是一个开源的分布式核算体系,具有内存核算、弹性调度、易用性等特色。Spark支撑多种数据处理形式,如批处理、流处理和交互式查询,适用于实时数据处理和剖析。
3. Flink:Flink是一个开源的分布式流处理结构,具有高功能、低推迟、容错性强等特色。Flink适用于实时数据处理和剖析,支撑事情驱动和微批处理形式。
大数据分布式核算使用场景
1. 互联网数据发掘:经过大数据分布式核算,能够对海量互联网数据进行发掘,提取有价值的信息,如用户行为剖析、广告投进优化等。
2. 日志剖析:企业能够经过大数据分布式核算对海量日志数据进行剖析,发现潜在问题,优化体系功能。
3. 商业智能:大数据分布式核算能够协助企业从海量数据中提取有价值的信息,为决议计划供给支撑,如市场剖析、客户画像等。
4. 金融风控:大数据分布式核算能够用于金融风控范畴,对海量买卖数据进行实时剖析,辨认潜在危险。
大数据分布式核算发展趋势
2. 实时数据处理:跟着实时数据处理需求的添加,大数据分布式核算将愈加重视实时性,进步数据处理速度。
3. 跨渠道兼容性:大数据分布式核算将愈加重视跨渠道兼容性,支撑更多类型的硬件和操作体系。
4. 开源生态继续完善:跟着开源社区的不断发展,大数据分布式核算的开源生态将继续完善,为用户供给更多挑选。
大数据分布式核算作为一种高效处理海量数据的技能,在各个范畴都得到了广泛使用。跟着技能的不断发展,大数据分布式核算将愈加老练,为企业和个人供给愈加快捷、高效的数据处理服务。
相关
-
or数据库,交融联系型与目标型数据库的优势详细阅读

1.强壮的数据办理才能:Oracle数据库可以处理很多的数据,支撑杂乱的数据查询和事务处理。2.高可用性:Oracle数据库供给了多种高可用性解决方案,如数据仿制、毛病搬运...
2024-12-23 0
-
大数据与财政办理,大数据年代背景下的财政办理革新详细阅读

1.数据搜集:大数据与财政办理首要需求搜集很多的财政数据,包含收入、开销、财物、负债等。这些数据能够来自企业的内部体系,如ERP(企业资源方案)体系,也能够来自外部数据源,如...
2024-12-23 0
-
cda大数据剖析师,数据年代的中心力气详细阅读

CDA(CertifiedDataAnalyst)大数据剖析师认证是在数字经济和人工智能年代背景下,面向全作业的数据剖析专业人才作业认证。以下是关于CDA大数据剖析师的一些...
2024-12-23 0
-
我国科学引文数据库,我国科学引文数据库(CSCD)在科研范畴的重要位置详细阅读

我国科学引文数据库(ChineseScienceCitationDatabase,简称CSCD)是一个重要的学术资源数据库,创立于1989年。以下是该数据库的详细介绍:...
2024-12-23 0
-
云数据库办理,云数据库办理的中心要素与最佳实践详细阅读

云数据库办理是指经过云核算渠道进行数据库的创立、布置、维护和扩展的进程。这种办理方式运用云核算的弹性和可扩展性,答应用户依据需求快速调整资源,然后进步数据库的功用和牢靠性。云数...
2024-12-23 0
-
才智大数据,驱动未来开展的中心动力详细阅读

“才智大数据”是指运用大数据技能,对海量数据进行高效处理、剖析和发掘,以完成智能化决议计划和办理的理念。它着重的是在大数据的基础上,经过先进的数据处理和剖析技能,如人工智能、机...
2024-12-23 0
-
审计数据库详细阅读

审计数据库是一个用于记载和盯梢数据库活动的进程,它供给了数据库操作的可追溯性和透明性。这有助于保证数据库的安全性和合规性,并协助安排恪守相关的法规和规范。审计数据库一般触及以下...
2024-12-23 0
-
大数据怎样查个人信息,大数据年代怎么查询个人信息详细阅读

大数据自身并不直接用于查询个人信息,它是一种剖析很多数据的技能和办法。在遵从相关法律法规和隐私维护的前提下,大数据能够用于辅佐剖析和研讨,以供给趋势猜测、市场剖析等服务。如果您...
2024-12-23 0
-
大数据开发项目,大数据开发项目概述详细阅读

大数据开发项目一般触及处理、存储和剖析很多数据,以提取有价值的信息和洞悉。以下是一个大数据开发项目的示例,包含其方针、技能栈和施行进程:项目方针:构建一个大数据渠道,用于搜集...
2024-12-23 0
-
mysql格局化时刻函数,MySQL格局化时刻函数概述详细阅读

1.`DATE_FORMAT`:将日期格局化为指定的格局。例如:```sqlSELECTDATE_FORMAT,'%Y%m%d%H:%i:%s'qwe2;```输出成...
2024-12-23 0