
机器学习 聚类,什么是聚类剖析?
聚类(Clustering)是机器学习范畴中的一种无监督学习技能,首要用于将数据会集的方针依照类似性分组。聚类算法的方针是将类似的方针归为一类,而将不类似的方针归为不同的类。这种分组能够协助咱们更好地舆解数据,发现数据中的形式,并做出决议计划。
在聚类剖析中,咱们一般不会事前知道数据应该被分为多少类,而是经过算法来自动地确认最佳的类别数量。聚类剖析的使用十分广泛,包含商场细分、客户联系办理、图画处理、社会网络剖析等范畴。
常见的聚类算法包含:
1. K均值聚类(KMeans Clustering):是一种简略且常用的聚类算法,它将数据分为 K 个簇,其间 K 是一个用户指定的参数。算法经过迭代的办法更新簇的中心点,直到满意特定的收敛条件。
2. 层次聚类(Hierarchical Clustering):这种聚类办法将数据方针依照类似度逐渐兼并或割裂成不同的簇。它有两种首要类型:自底向上的凝集层次聚类和自顶向下的割裂层次聚类。
3. 密度聚类(DensityBased Clustering):如 DBSCAN(DensityBased Spatial Clustering of Applications with Noise)算法,它依据数据点的部分密度来发现簇,并能够辨认出噪声点。
4. 谱聚类(Spectral Clustering):这种办法使用数据的谱图理论来聚类,一般用于处理非线性数据。
聚类算法的挑选取决于数据的特色和聚类方针。在实践使用中,或许需求测验多种算法,并对成果进行评价,以确认最适合特定问题的聚类办法。
机器学习中的聚类剖析:探究数据内涵结构的办法
什么是聚类剖析?
聚类剖析的重要性
聚类剖析在数据发掘和机器学习范畴具有广泛的使用,其重要性首要体现在以下几个方面:
发现数据散布和特征:聚类剖析能够协助咱们了解数据的内涵结构和规则,发现潜在的数据形式。
辨认异常值和噪声:经过聚类剖析,咱们能够辨认出数据中的异常值或噪声,然后进步数据质量。
供给先验常识:聚类剖析的成果能够为后续的监督学习供给有价值的先验常识,如初始化分类器的参数等。
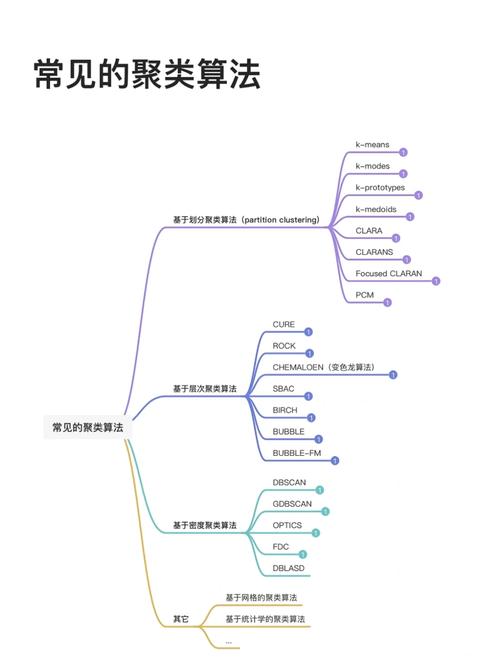
常见的聚类算法
在机器学习中,常见的聚类算法包含K-Means、层次聚类、DBSCAN等。以下是几种常见的聚类算法及其特色:
K-Means算法
K-Means算法是一种依据区分的聚类算法,其基本思想是将数据区分为K个簇,使得每个簇内的数据点到其所属簇的质心(centroid)的间隔之和最小。K-Means算法的长处是简略高效,但缺陷是需求预先指定簇的数量K,且对异常值灵敏。
层次聚类
层次聚类是一种依据层次结构的聚类算法,它将数据集逐渐兼并成簇,直到到达指定的簇数量。层次聚类算法的长处是无需预先指定簇的数量,但缺陷是核算复杂度较高。
DBSCAN算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种依据密度的聚类算法,它将数据点分为簇,一起考虑数据点的密度和间隔。DBSCAN算法的长处是能够处理非凸形状的簇,且对异常值不灵敏,但缺陷是参数较多,需求依据具体问题进行调整。
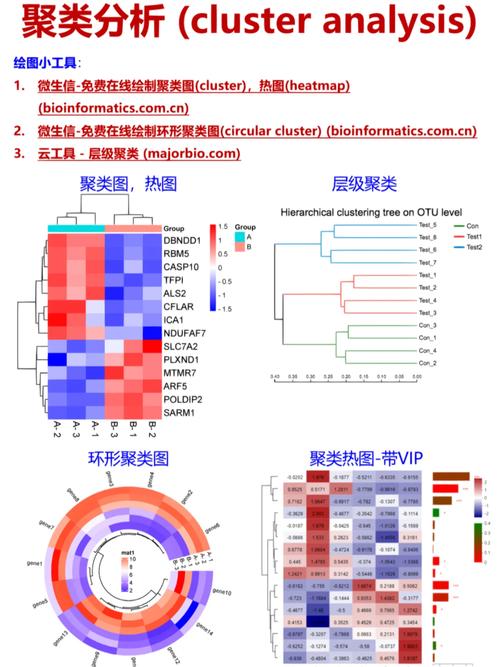
聚类剖析的使用
聚类剖析在许多范畴都有着广泛的使用,以下罗列几个比如:
图画处理:聚类剖析能够用于图画切割、色彩量化等使命。
商场剖析:聚类剖析能够协助企业完成客户细分,拟定更精准的营销战略。
生物信息学:聚类剖析能够用于基因表达数据的剖析,提醒基因之间的相互作用联系。
聚类剖析是机器学习范畴中一种重要的无监督学习办法,它能够协助咱们探究数据的内涵结构,发现潜在的形式。在实践使用中,挑选适宜的聚类算法和参数关于得到精确的成果至关重要。跟着机器学习技能的不断发展,聚类剖析将在更多范畴发挥重要作用。
相关
-
百变机器学习,探究人工智能的无限或许详细阅读

“百变机器学习”实际上是指《百面机器学习》这本书。该书由诸葛越编写,首要涵盖了机器学习范畴的多个方面,旨在协助读者构建一个全面的机器学习常识体系。书中具体介绍了特征工程、模型评...
2024-12-26 2
-
神经网络与机器学习,探究智能年代的核心技能详细阅读

神经网络和机器学习是两个密切相关但有所区别的概念。神经网络是一种仿照人脑作业原理的核算模型,由很多彼此衔接的神经元组成。每个神经元接纳输入信号,经过激活函数处理这些信号,然后输...
2024-12-26 2
-
机器学习吴恩达笔记,浅显易懂吴恩达机器学习笔记——敞开AI学习之旅详细阅读

1.知乎专栏:2.CSDN博客:3.GitHub资源:这些资源涵盖了吴恩达机器学习课程的各个章节,包含线性...
2024-12-26 2
-
形式辨认与机器学习,技能交融与未来展望详细阅读

形式辨认与机器学习是两个严密相关但又有差异的范畴。它们都是人工智能的子范畴,致力于让计算机可以从数据中学习并做出决议计划。形式辨认首要重视怎么自动辨认和分类数据中的形式。它一般...
2024-12-26 2
-
机器学习 mobi详细阅读

基本概念机器学习是一门多范畴交叉学科,触及概率论、统计学、迫临论、算法杂乱度理论等多门学科。其主要研讨核算机怎么模仿或完成人类的学习行为,以获取新的常识或技能,重新组织已有的...
2024-12-26 2
-
ai归纳点评办法,全面解析与未来展望详细阅读

1.精确性点评:经过比较AI体系或模型的输出与实在值或专家判别,来点评其精确性。这一般涉及到核算各种目标,如精确率、召回率、F1分数等。2.稳定性点评:点评AI体系或模型在...
2024-12-26 3
-
48ai归纳,探究人工智能在各个范畴的使用与应战详细阅读

PreSonusStudioLive48AIMixSystem是一款功用强壮的48通道数字调音台体系,适用于各种现场表演和专业录音环境。以下是该体系的具体特色:1....
2024-12-26 4
-
机器人课程学习,敞开未来科技之旅详细阅读

机器人课程学习指南1.了解机器人根底常识:机器人分类:了解不同类型的机器人,例如工业机器人、服务机器人、特种机器人等,以及它们的运用范畴。机器人结构:学...
2024-12-26 3
-
ai软件,技能革新与职业运用详细阅读

1.归纳类AI东西:百度文心一言:百度推出的依据文心大模型的AI对话产品,支撑对话互动、问题答复和创造帮忙。阿里通义千问:背靠阿里云强壮的核算才能和数据资源,...
2024-12-26 4
-
ai归纳数据,驱动未来智能开展的中心动力详细阅读

关于AI归纳数据,以下是几份具体的陈述和研讨,供您参阅:1.2024年我国AI根底数据服务研讨陈述:该陈述由我国信息通讯研讨院发布,具体剖析了我国AI根底数据服务商场的...
2024-12-26 2