
spark 机器学习,高效处理大数据的利器
Apache Spark 是一个强壮的开源数据处理结构,它供给了丰厚的机器学习库,称为 MLlib。MLlib 包含了多种机器学习算法,包含分类、回归、聚类、协同过滤、决策树、随机森林和梯度进步树等。
以下是运用 Spark 进行机器学习的一些根本过程:
1. 数据预备:首要,需求加载数据并将其转换为 Spark DataFrame 或 Dataset 格局。这能够经过读取文件(如 CSV、JSON、Parquet 等)或连接到数据库来完成。
2. 数据预处理:数据预处理或许包含缺失值处理、特征缩放、特征编码、特征挑选等。Spark 供给了多种数据预处理东西,如 `VectorAssembler`、`StringIndexer`、`OneHotEncoder`、`StandardScaler` 等。
3. 模型练习:挑选恰当的机器学习算法并运用练习数据练习模型。Spark 供给了多种算法完成,如 `LinearRegression`、`LogisticRegression`、`RandomForestClassifier`、`KMeans` 等。
4. 模型评价:运用测试数据评价模型的功用。Spark 供给了多种评价目标,如准确率、召回率、F1 分数、均方差错(MSE)等。
5. 模型调优:依据评价成果调整模型参数以优化功用。这能够经过网格查找、随机查找或贝叶斯优化等方法来完成。
6. 模型布置:将练习好的模型布置到出产环境中,以便对新数据进行猜测。
7. 模型监控:在出产环境中监控模型的功用,以保证其继续有用。
8. 模型更新:跟着时刻的推移,或许需求对模型进行更新以习惯新的数据或改变的环境。
以下是一个简略的示例,展现了怎么运用 Spark MLlib 练习一个线性回归模型:
```pythonfrom pyspark.sql import SparkSessionfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.regression import LinearRegression
创立 Spark 会话spark = SparkSession.builder.appName.getOrCreate
加载数据data = spark.read.csv
数据预处理assembler = VectorAssembler, outputCol=featuresqwe2data = assembler.transform
区分数据集train_data, test_data = data.randomSplitqwe2
封闭 Spark 会话spark.stop```
请注意,这仅仅一个简略的示例,实践的机器学习项目或许需求更杂乱的数据预处理、模型挑选和调优过程。此外,Spark 还支撑更高档的机器学习功用,如管道(Pipeline)、参数服务器(Parameter Server)等。
深化探究 Apache Spark 机器学习:高效处理大数据的利器
跟着大数据年代的到来,怎么高效处理和剖析海量数据成为了企业和研究机构重视的焦点。Apache Spark 作为一款强壮的分布式核算引擎,凭仗其高功用和易用性,在数据处理和剖析范畴得到了广泛运用。本文将深化探讨 Apache Spark 机器学习,剖析其在处理大数据方面的优势和运用场景。
一、Apache Spark 机器学习概述
Apache Spark MLlib 是 Spark 生态体系中的一个重要组件,供给了丰厚的机器学习算法和东西。MLlib 支撑多种机器学习算法,包含分类、回归、聚类、降维等,能够满意不同场景下的需求。
二、Apache Spark 机器学习的优势
1. 高效处理大数据:Spark MLlib 依据Spark的分布式核算结构,能够高效处理大规模数据集,完成并行核算,进步数据处理速度。
2. 丰厚的算法库:Spark MLlib 供给了多种机器学习算法,便利用户依据实践需求挑选适宜的算法。
3. 易于运用:Spark MLlib 供给了简练的 API,用户能够轻松完成机器学习使命。
4. 与其他组件集成:Spark MLlib 能够与其他 Spark 组件(如 Spark SQL、Spark Streaming)无缝集成,完成数据处理的完好流程。
三、Apache Spark 机器学习运用场景
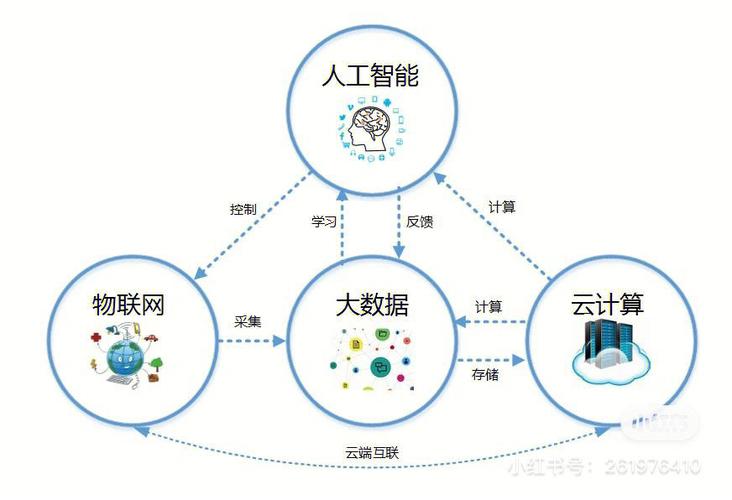
1. 数据发掘:Spark MLlib 能够用于数据发掘使命,如聚类、分类、相关规矩发掘等,协助用户发现数据中的潜在规则。
2. 机器学习模型练习:Spark MLlib 支撑多种机器学习算法,能够用于练习模型,如线性回归、决策树、随机森林等。
3. 实时引荐体系:Spark MLlib 能够与 Spark Streaming 结合,完成实时引荐体系,为用户供给个性化的引荐服务。
4. 图剖析:Spark MLlib 支撑图剖析算法,能够用于交际网络剖析、引荐体系等场景。
四、Apache Spark 机器学习实践
以下是一个简略的 Apache Spark 机器学习实践事例,运用 Spark MLlib 进行线性回归模型练习。
```java
// 创立 SparkContext
SparkContext sc = new SparkContext(\
相关
-
机器学习会议,探究机器学习范畴的未来趋势详细阅读

1.ACML(AsianConferenceonMachineLearning)简介:ACML是一个旨在促进机器学习研讨和实践的世界性会议。内容:会议...
2024-12-27 0
-
机器学习招聘,探究AI年代的工作新机会详细阅读

1.BOSS直聘:BOSS直聘供给2024年最新的机器学习招聘信息,支撑在线开聊、在线面试,方便快捷。你能够拜访获取更多信息。2.猎聘网:猎聘网供给很多机器...
2024-12-27 0
-
智能英语学习机器人,未来英语学习的得力助手详细阅读

智能英语学习机器人:未来英语学习的得力助手一、智能英语学习机器人的功用智能英语学习机器人具有以下功用:个性化学习计划:依据学生的学习水平缓需求,智能英语学习机器人可以供给个...
2024-12-27 0
-
机器学习数学建模,机器学习在数学建模中的运用与应战详细阅读

机器学习数学建模是运用数学办法和东西来树立和描绘机器学习模型的进程。它涉及到对数据的数学表明、模型的数学表达以及模型的求解和优化。以下是机器学习数学建模的一些关键步骤:1.数...
2024-12-27 0
-
归纳国产ai换脸,国产AI换脸技能开展现状与应战详细阅读

1.DeepSwapper特色:完全免费且无限制的AI换脸东西,支撑图片和视频换脸功用,无需注册登录,无广告,高质量换脸作用。2.FaceSwapAI...
2024-12-27 0
-
ai归纳动力,构建才智动力新生态详细阅读

AI技能在归纳动力范畴的运用正在不断深化,包含多个方面,包含动力体系的优化、猜测与调度、设备智能化改造、新动力开发与运用等。以下是AI归纳动力的首要运用方向和趋势:1.动力体...
2024-12-27 0
-
归纳点评自我陈说ai,AI助力归纳点评自我陈说,敞开特性化展现新篇章详细阅读

AI技能,特别是自然言语处理和机器学习的开展,现已使得自我陈说的生成成为或许。AI生成的自我陈说是否可以精确、全面地反映个人的特质、阅历和方针,是一个值得讨论的问题。AI生成自...
2024-12-27 0
-
机器学习 标签详细阅读
数据增强:经过数据增强技能,生成更多具有代表性的数据。运用无监督学习:运用无监督学习方法,发现数据中的潜在形式。运用半监督学习:运用部分符号数据和未符号数据,练习模...
2024-12-27 0
-
ai脚本,主动化年代的得力帮手详细阅读

AI脚本一般指的是用于操控或主动化人工智能体系的程序或脚本。这些脚本可所以用各种编程言语编写的,如Python、JavaScript、C等。AI脚本能够用于多种意图,例如:...
2024-12-27 0
-
机器学习实战视频,机器学习实战视频教程全解析详细阅读

1.哔哩哔哩上的课程:机器学习全套课程从入门到实战:这套课程共有81条视频,包含了从什么是机器学到特征工程等内容。概况请见。肯定是全网最简略的机器学习实战教...
2024-12-27 0