
聚类机器学习, 什么是聚类机器学习
聚类是一种无监督学习的办法,首要用于将数据集分为不同的组或“簇”,使得同一簇内的数据点互相类似,而不同簇的数据点则互相不类似。这种办法在许多范畴都有使用,比方商场细分、客户联系办理、图画处理和交际网络剖析等。
在聚类算法中,常见的有K均值聚类、层次聚类、DBSCAN等。K均值聚类是一种根据间隔的算法,它将数据集分为K个簇,每个簇由一个中心点代表。层次聚类则是一种根据树结构的算法,它将数据集逐渐兼并或割裂成不同的簇。DBSCAN是一种根据密度的算法,它能够将具有满足高密度的区域划分为簇,而将低密度的区域视为噪声。
聚类算法的挑选取决于数据的特色和聚类方针。在实践使用中,一般需求经过试验和调整参数来找到最佳的聚类计划。
聚类机器学习:探究数据内涵结构的新办法
什么是聚类机器学习

聚类算法概述
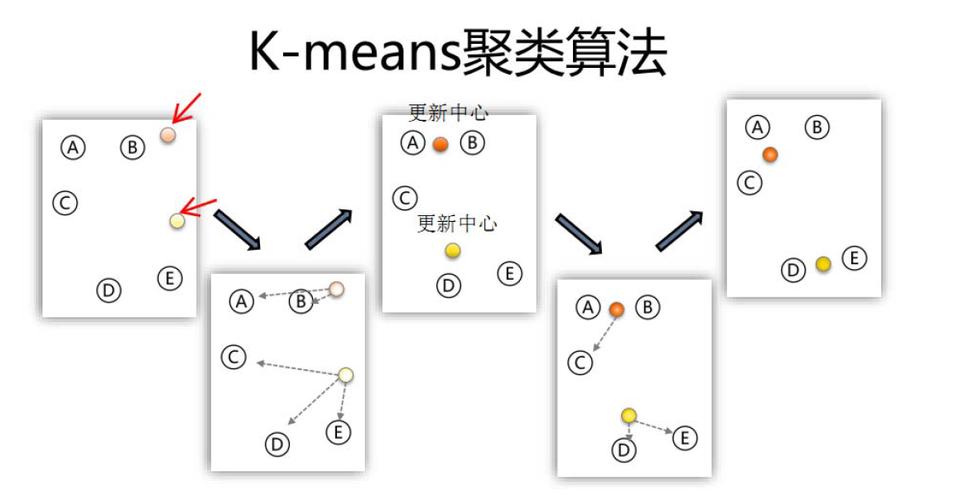
K-Means算法:根据间隔的聚类算法,经过迭代核算簇中心,将数据点分配到最近的簇中心。
层次聚类:经过兼并或割裂簇来构建一个树状结构,称为聚类树或谱系图。
DBSCAN算法:根据密度的聚类算法,能够辨认恣意形状的簇,并能够处理噪声和反常值。
谱聚类:经过剖析数据点的类似性矩阵来辨认簇,适用于高维数据。
聚类算法的挑选
数据类型:不同的聚类算法适用于不同类型的数据,例如,K-Means适用于数值型数据,而层次聚类适用于任何类型的数据。
数据规划:关于大规划数据集,一些算法或许比其他算法更高效。
簇的形状:不同的算法对簇的形状有不同的假定,例如,K-Means假定簇是球形的,而DBSCAN能够辨认恣意形状的簇。
噪声和反常值:一些算法对噪声和反常值更鲁棒,例如,DBSCAN能够处理噪声和反常值。
聚类成果的评价

概括系数:衡量簇内数据点之间的类似性和簇间数据点之间的差异性。
Calinski-Harabasz指数:衡量簇内数据点之间的类似性和簇间数据点之间的差异性,但比概括系数更敏感于簇的巨细。
Davies-Bouldin指数:衡量簇内数据点之间的类似性和簇间数据点之间的差异性,但比Calinski-Harabasz指数更敏感于簇的形状。
聚类在实践使用中的事例
商场细分:经过聚类剖析,企业能够将客户分为不同的集体,以便更好地了解客户需求,拟定营销战略。
图画辨认:聚类算法能够用于图画辨认使命,例如,将图画中的目标分为不同的类别。
交际网络剖析:聚类算法能够用于剖析交际网络中的用户联系,辨认社区和子群。
聚类机器学习是一种强壮的东西,能够协助咱们探究数据中的内涵结构。经过挑选适宜的算法、评价聚类成果,并在实践使用中使用聚类技能,咱们能够从数据中取得有价值的见地。
相关
-
机器学习 在线学习,敞开智能年代的学习之旅详细阅读
机器学习在线课程引荐1.吴恩达的“机器学习”公开课渠道:Coursera言语:英语,供给中文字幕特色:这是最受欢迎的机器学习入门课程,侧重于概...
2024-12-30 11
-
机器学习小样本,机器学习中的高效处理方案详细阅读
机器学习小样本问题是指在运用机器学习算法时,数据集的样本数量十分有限的状况。在传统的大数据年代,机器学习算法一般依赖于很多的数据来练习模型,然后进步模型的精确性和泛化才能。在许...
2024-12-30 12
-
ai归纳操练,从根底到进阶的全面攻略详细阅读
1.图画辨认与分类:运用深度学习模型,如卷积神经网络(CNN),对图画进行分类,如辨认手写数字、动物、植物等。2.文本剖析:运用自然语言处理技术,如词嵌入、文本分类、情感剖...
2024-12-30 10
-
ai英语,AI技能怎么重塑英语学习体会详细阅读
1.英语学习软件:许多英语学习软件都使用了AI技能,如智能语音辨认、自然言语处理和机器学习,来协助用户进步英语听、说、读、写才能。例如,Duolingo、RosettaSt...
2024-12-30 11
-
ai艺术字,构思无限,规划新潮流详细阅读

AI艺术字一般指的是运用人工智能技能来规划和生成具有艺术感的字体。这种技能可以主动生成一起、构思和特性化的字体,为规划师供给更多挑选和构思。AI艺术字的运用规模广泛,包含平面规...
2024-12-30 9
-
哩布哩布ai官网,探究哩布哩布AI官网,敞开智能日子新篇章详细阅读

哩布哩布AI官网是一个专业的AI创造渠道,供给多种类型的AI创造东西和服务。以下是该渠道的一些主要特点:1.丰厚的模型资源:渠道上具有超越10万个免费的AI绘画原创模型,用户...
2024-12-30 9
-
机器学习吴恩达作业,从根底到实战详细阅读

1.知乎上的资源::供给了吴恩达《机器学习》课程的Python版编程作业和Quiz的中文版,可以在线运转和测验。还引荐了课程的视频、笔记和其他资源。2.CSDN上的...
2024-12-30 12
-
机器学习 特征提取,特征提取的重要性详细阅读

机器学习中的特征提取是一个要害过程,它涉及到从原始数据中提取出有用的信息,以便机器学习模型能够更好地学习和猜测。特征提取的意图是将原始数据转换成机器学习算法能够了解的格局,并削...
2024-12-30 9
-
奇域ai,东方美学的数字展示详细阅读

奇域AI是一个专心于中式审美和国风艺术的AI绘画创造渠道。它使用人工智能技能,经过文字描述生成具有我国文明特征的绘画著作。以下是奇域AI的一些主要特色和功用:1.中式美学创造...
2024-12-30 8
-
机器学习与经济学,立异与应战详细阅读
机器学习与经济学的交融:立异与应战一、机器学习在经济学中的使用机器学习在经济学中的使用首要体现在以下几个方面:1.猜测市场趋势:经过剖析历史数据,机器学习模型能够猜测股票价格...
2024-12-30 9