
机器学习的内容,界说与概述
机器学习是人工智能的一个分支,它使核算机体系能够从数据中学习并做出决议计划,而不需要显式地进行编程。机器学习经过算法来剖析数据、识别形式,并据此做出猜测或决议计划。这些算法能够主动优化,以便更好地从经历中学习。机器学习通常被分为监督学习、无监督学习和强化学习三类。
2. 无监督学习:与监督学习不同,无监督学习不依赖于已知的输出成果。它经过寻觅数据中的形式和联系来学习。例如,聚类算法能够用来将数据点分组,而相关规则学习能够用来发现数据项之间的相关性。
3. 强化学习:强化学习是一种经过奖赏和赏罚来练习智能体的办法。智能体在环境中采纳举动,并依据其举动的成果取得奖赏或赏罚。经过这种方法,智能体能够学习到在特定环境中采纳最佳举动的战略。
机器学习在许多范畴都有广泛的运用,包含但不限于自然语言处理、核算机视觉、引荐体系、金融猜测、医疗确诊等。跟着大数据和核算才能的进步,机器学习在处理杂乱问题方面的才能也在不断增强。
机器学习:界说与概述
机器学习(Machine Learning,ML)是人工智能(Artificial Intelligence,AI)的一个重要分支,它使核算机体系能够从数据中学习并做出决议计划或猜测,而无需显式编程。机器学习的关键在于算法,这些算法能够从数据中提取形式,并运用这些形式来做出决议计划。
机器学习的基本概念
机器学习的基本概念包含以下几个要素:
数据:机器学习依赖于很多数据来练习模型。
算法:这些是用于从数据中学习并提取形式的数学公式。
模型:模型是算法处理数据后构成的输出,能够用于猜测或分类。
练习:这是将数据输入到算法中,使其能够学习的进程。
测验与验证:这是评价模型功能的进程,保证模型在不知道数据上的体现杰出。
机器学习的类型
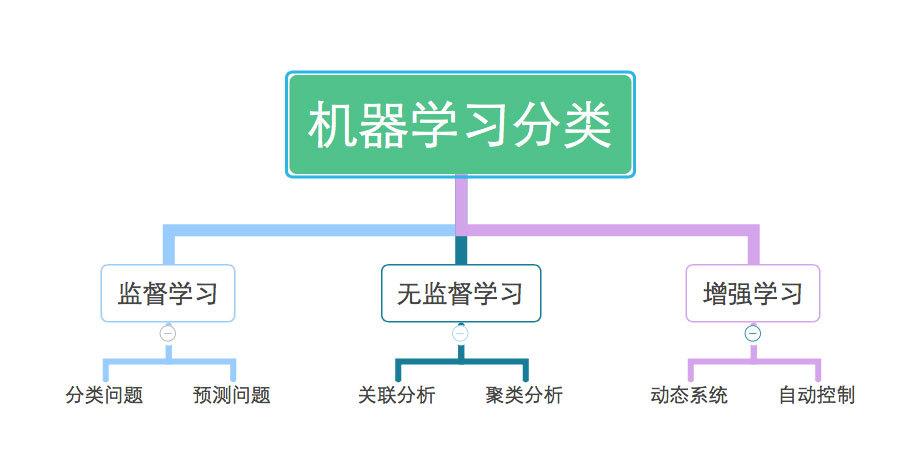
依据学习方法和运用场景,机器学习能够分为以下几种类型:
监督学习(Supervised Learning):在这种学习中,算法从符号的练习数据中学习,以便在测验数据上进行猜测。
无监督学习(Unsupervised Learning):在这种学习中,算法处理未符号的数据,寻觅数据中的形式或结构。
半监督学习(Semi-supervised Learning):结合了监督学习和无监督学习,运用少数符号数据和很多未符号数据。
强化学习(Reinforcement Learning):在这种学习中,算法经过与环境的交互来学习,并根据奖赏和赏罚来优化其行为。
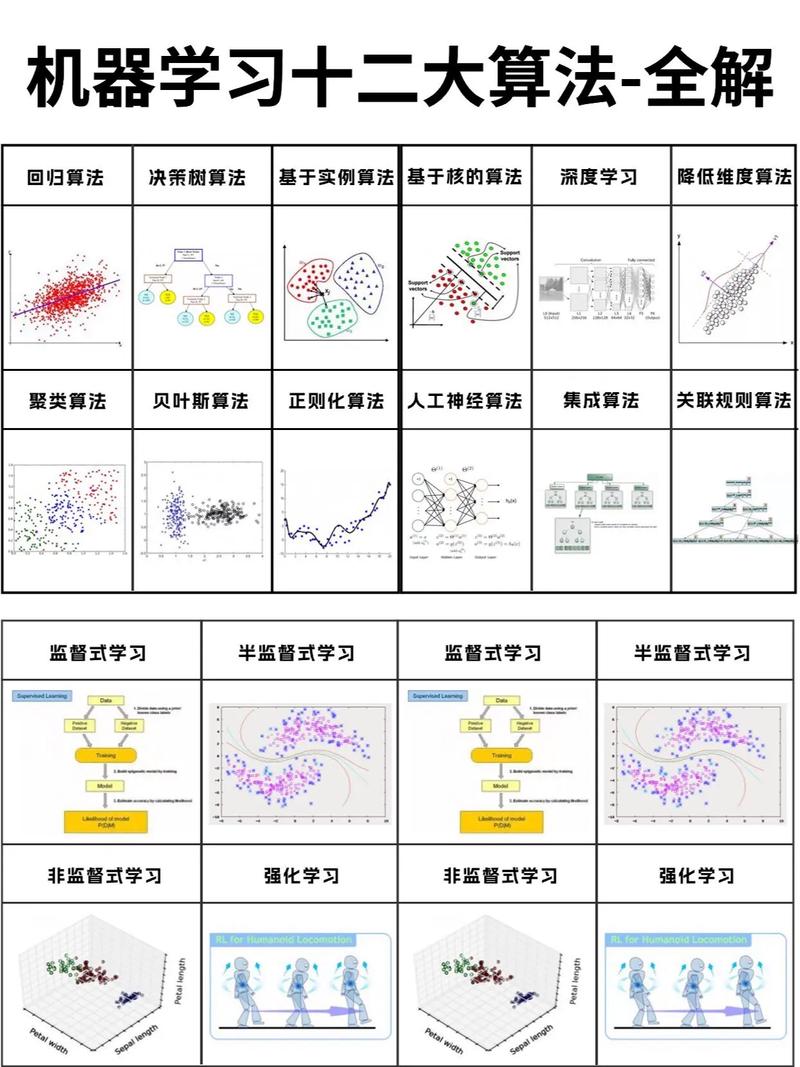
常见的机器学习算法

线性回归(Linear Regression):用于猜测接连值。
逻辑回归(Logistic Regression):用于猜测二元分类问题。
支撑向量机(Support Vector Machine,SVM):用于分类和回归问题。
决议计划树(Decision Trees):用于分类和回归问题,易于了解和解说。
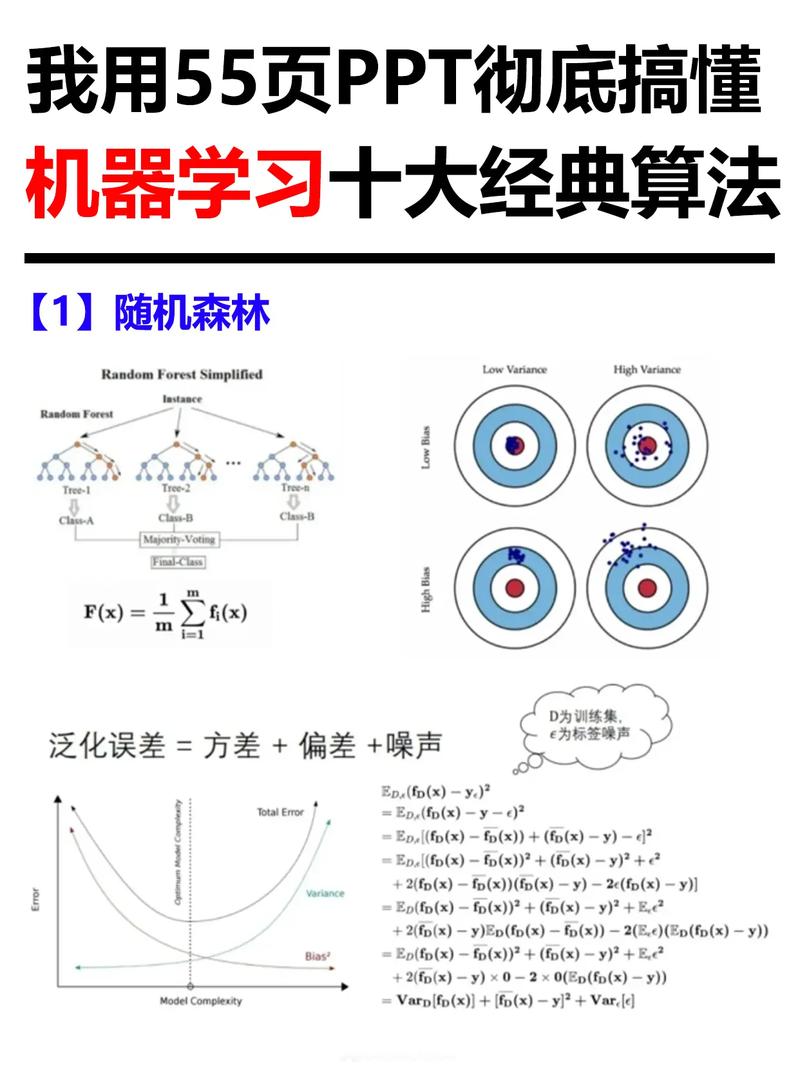
随机森林(Random Forest):经过构建多个决议计划树来进步猜测准确性。
神经网络(Neural Networks):仿照人脑神经元的工作方法,用于杂乱的形式识别。
机器学习的应战与未来趋势

虽然机器学习取得了明显的发展,但仍面对一些应战:
数据质量:机器学习依赖于高质量的数据,数据质量问题会影响模型的功能。
可解说性:许多高档机器学习模型,如深度学习,被认为是“黑箱”,其决议计划进程难以解说。
算法成见:假如练习数据存在成见,机器学习模型或许会扩大这些成见。
未来,机器学习的趋势或许包含:
可解说人工智能(XAI):开发更可解说的机器学习模型。
联邦学习(Federated Learning):在维护数据隐私的一起进行模型练习。
跨学科研讨:结合心理学、社会学和经济学等范畴的研讨,以更好地了解人类行为。
定论

机器学习作为人工智能的核心技能之一,正在改变着各行各业。跟着技能的不断进步和运用的深化,机器学习将持续推进立异,并为处理杂乱问题供给新的处理方案。
相关
-
机器学习开源结构,构建智能国际的柱石详细阅读

1.TensorFlow:由Google开发,是一个广泛运用的开源机器学习结构,支撑深度学习和自然言语处理等使命。2.PyTorch:由Facebook开发,是一个动态核算...
2024-12-29 1
-
java 机器学习库,助力开发者构建智能运用详细阅读

1.Weka:Weka是一个开源的机器学习库,它供给了很多的数据预处理、分类、回归、聚类和相关规矩发掘算法。Weka特别适宜于教育和研讨,由于它供给了图形用户界面,能够轻...
2024-12-29 1
-
连绵冰机器学习,立异技能助力甜品职业晋级详细阅读

1.北极海冰猜测:多种机器学习算法的运用:在北极海冰猜测中,多种机器学习算法如支撑向量机(SVR)、深度森林(DF)、LightGBM(LGB)、XGBoost(XG...
2024-12-29 1
-
python机器学习书本,书本引荐与学习指南详细阅读

入门书本1.《Python机器学习根底教程》这本书由图灵出品,首要介绍了Python在机器学习范畴的根底常识和常用技能,包含数学根底、数据预处理、特征工程、模型评价...
2024-12-29 2
-
电脑机器人编程学习,敞开未来科技之旅详细阅读

电脑机器人编程学习指南学习电脑机器人编程是一个风趣且赋有挑战性的进程,它涵盖了多个范畴,包含编程言语、算法、人工智能、机器人学等。以下是一个学习途径,协助你逐渐把握电脑机器人...
2024-12-29 2
-
ai官网,探究AI范畴的无限或许——XX智能官网全新上线!详细阅读

您好,请问您详细想了解哪方面的AI官网信息?例如,假如您想了解百度AI敞开途径,能够拜访。假如您有其他特定的需求,请告诉我,我会极力为您供给协助。探究AI范畴的无限或许——XX...
2024-12-29 4
-
屠戮机器学习,什么是屠戮机器学习?详细阅读

什么是屠戮机器学习?屠戮机器学习是指运用机器学习技能,使机器具有自主决议计划和履行屠戮的才干。这种技能一般触及以下几个方面:方针辨认:经过图画辨认、声响辨认等技能,机器...
2024-12-29 4
-
ai生长归纳点评,技能前进与未来展望详细阅读

AI的生长归纳点评是一个杂乱的问题,由于AI的生长涉及到多个方面,包含技能开展、使用车开展,促进AI技能的立异和使用。6.国际协作:AI技能的开展需求全球范围内的协作。各国政...
2024-12-29 5
-
ai模型归纳,AI模型归纳概述详细阅读

AI模型归纳是指将多个AI模型组合在一起,以完成更杂乱、更强壮的功用。这种归纳可以包含不同类型的模型,例如将深度学习模型与传统的机器学习模型相结合,或许将不同的深度学习模型(如...
2024-12-29 4
-
ai我国,兴起之路与未来展望详细阅读
1.工业规划与技能立异到2023年6月,我国人工智能中心工业规划现已到达5000亿元,人工智能企业数量超越4400家,仅次于美国,全球排名第二。在技能立异方面,我国在大模型...
2024-12-28 5