
python爬虫教程
学习爬虫技能,你能够经过以下过程来入门和进阶:
1. 了解爬虫的根本概念: 爬虫是什么?它的效果是什么? 爬虫的分类:通用爬虫和聚集爬虫。 爬虫的道德和法律问题。
2. 学习HTML和CSS: 了解HTML的根本结构。 学习怎么运用CSS挑选器来定位网页元素。
3. 学习Python编程根底: 装置Python环境。 学习Python的根本语法和数据结构。 把握Python的文件读写操作。
4. 学习网络恳求和呼应: 运用`requests`库发送HTTP恳求。 了解HTTP呼应和状况码。 学习怎么处理恳求头和呼应头。
5. 学习解析HTML文档: 运用`BeautifulSoup`或`lxml`库解析HTML文档。 学习怎么提取文本、链接、图片等数据。 了解CSS挑选器和XPath表达式。
6. 学习正则表达式: 了解正则表达式的根本语法和形式。 学习怎么运用正则表达式提取特定的文本形式。
7. 学习多线程和多进程: 了解多线程和多进程的概念。 学习怎么运用`threading`和`multiprocessing`库来前进爬虫的功率。
8. 学习反常处理和日志记载: 了解反常处理的根本概念。 学习怎么运用`tryexcept`句子捕获和处理反常。 了解日志记载的根本概念。 学习怎么运用`logging`库记载爬虫的运转日志。
9. 学习数据存储: 了解数据存储的根本概念。 学习怎么将爬取的数据存储到文件、数据库或CSV文件中。
10. 学习反爬虫机制和应对战略: 了解常见的反爬虫机制,如IP封禁、验证码、用户署理约束等。 学习怎么应对这些反爬虫机制,如运用署理IP、设置用户署理、处理验证码等。
11. 实践项目: 挑选一个实践的项目,如爬取某个网站的数据,来实践所学常识。 在实践中不断优化和改善爬虫的功用和安稳性。
12. 继续学习和进阶: 跟着技能的开展,爬虫技能也在不断更新和前进。 继续重视和学习新的爬虫技能和东西。
13. 参阅资源: 书本:《Python网络爬虫从入门到实践》、《Python 3网络爬虫开发实战》。 在线教程:廖雪峰的Python教程、菜鸟教程。 社区论坛:CSDN、GitHub、Stack Overflow。
14. 学习Python爬虫结构: 学习Scrapy结构,了解其架构和作业流程。 学习怎么运用Scrapy进行爬虫开发。 学习Scrapy的常用组件,如Downloader、Spider、Item Pipeline等。
15. 学习爬虫的测验和调试: 学习怎么运用测验结构进行爬虫的单元测验。 学习怎么运用调试东西进行爬虫的调试和问题排查。
16. 学习爬虫的布置和维护: 了解爬虫的布置方法,如本地布置、云服务器布置等。 学习怎么运用守时使命东西(如Cron)守时运转爬虫。 了解爬虫的维护和监控,保证爬虫的安稳运转。
17. 学习爬虫的高档技能: 学习爬虫的分布式爬取技能,如运用Redis和RabbitMQ完成分布式爬虫。 学习爬虫的动态网页烘托技能,如运用Selenium或Pyppeteer完成动态网页的爬取。 学习爬虫的数据发掘和剖析技能,如运用Numpy、Pandas、Matplotlib等东西进行数据剖析和可视化。
18. 学习爬虫的安全性和隐私维护: 了解爬虫的安全性问题,如SQL注入、XSS进犯等。 学习怎么维护爬虫的源代码和数据。 了解爬虫的隐私维护问题,如恪守网站的运用条款和隐私方针。
19. 学习爬虫的法律法规: 了解与爬虫相关的法律法规,如版权法、数据维护法等。 学习怎么合法合规地进行爬虫开发和运用。
20. 学习爬虫的社区和资源: 参加爬虫相关的社区和论坛,与其他爬虫开发者交流学习。 重视爬虫相关的博客、大众号和交际媒体,获取最新的技能动态和资讯。
经过以上过程,你能够逐渐把握Python爬虫技能,并能够独立开宣布功用强大、功用安稳的爬虫程序。
Python爬虫教程:从入门到实践
一、什么是爬虫?

爬虫,也称为网络爬虫或网络蜘蛛,是一种自动化程序,用于从互联网上抓取数据。Python作为一种功用强大的编程言语,具有丰厚的库和东西,使得爬虫的开发变得相对简单。本教程将带你从零开始,学习怎么运用Python进行网页爬虫开发。
二、Python爬虫的根本概念

1. 网页爬虫的界说:网页爬虫是一种自动化程序,能够遍历互联网上的网页,提取所需的数据。
2. 网页爬虫的分类:
通用爬虫:旨在抓取整个互联网上的网页,一般用于搜索引擎的索引构建。
聚集爬虫:专心于特定的主题或范畴,只抓取与特定主题相关的网页。
3. 网页爬虫的合法性:在进行网页爬虫开发时,需求留意恪守法律法规和网站的运用条款。一些网站或许制止爬虫拜访,或许对爬虫的拜访频率和行为进行约束。
三、Python爬虫开发环境建立
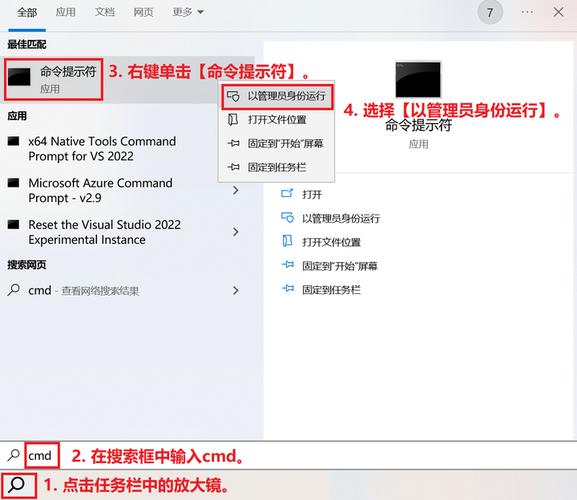
1. 装置Python:首要,保证你的核算机上现已装置了Python。能够从Python官方网站下载并装置最新版别的Python。
2. 装置第三方库:Python爬虫开发中常用的第三方库有requests、BeautifulSoup、lxml等。能够运用pip指令进行装置:
pip install requests
pip install beautifulsoup4
pip install lxml
四、运用requests库发送HTTP恳求
1. 导入requests库:

import requests
2. 发送GET恳求:

url = 'http://www.example.com'
response = requests.get(url)
3. 获取呼应内容:
print(response.text)
五、运用BeautifulSoup解析HTML内容
1. 导入BeautifulSoup库:
from bs4 import BeautifulSoup
2. 创立BeautifulSoup方针:
soup = BeautifulSoup(response.text, 'html.parser')
3. 查找元素:

title = soup.find('title').text
print(title)
六、数据提取与存储
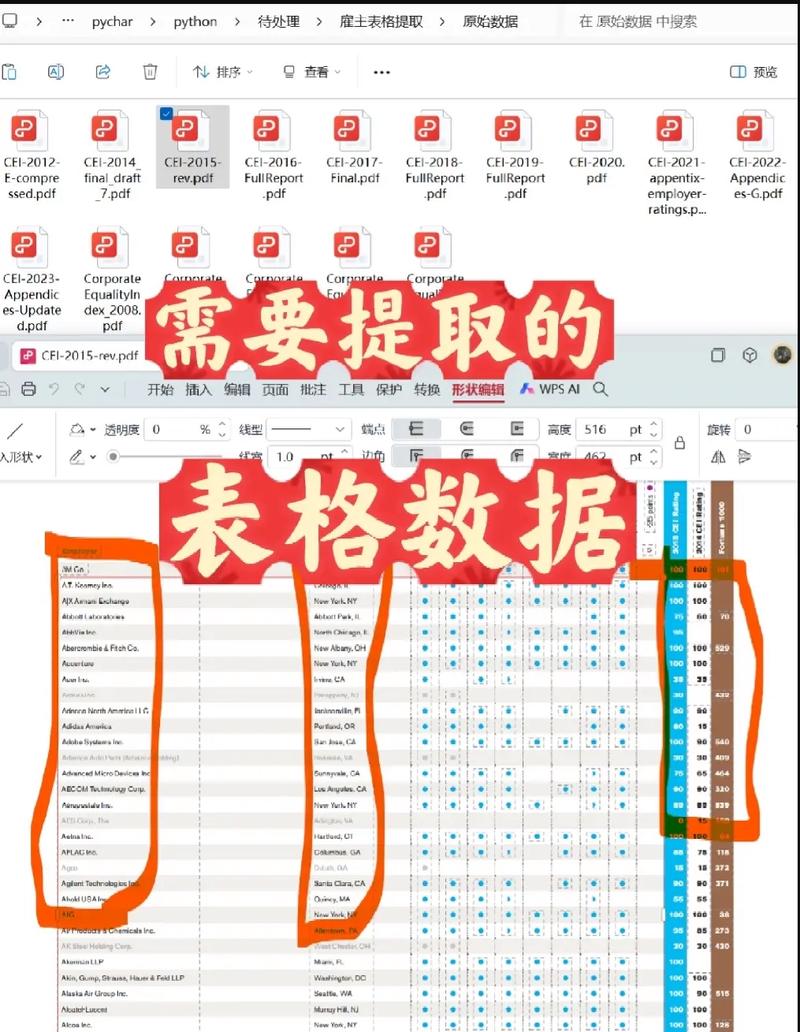
1. 提取所需数据:
titles = soup.find_all('title')
for title in titles:
print(title.text)
2. 存储数据:

with open('data.txt', 'w', encoding='utf-8') as f:
for title in titles:
f.write(title.text '\
七、留意事项

1. 恪守网站运用条款:在进行爬虫开发时,必须恪守方针网站的运用条款,防止对网站形成不必要的压力。

2. 合理设置恳求频率:防止短时间内发送很多恳求,避免对方针网站形成过大压力。
3. 处理反常:在爬虫开发过程中,或许会遇到各种反常情况,如网络连接过错、恳求超时等。需求合理处理这些反常,保证爬虫的安稳性。
经过本教程,你已把握了Python爬虫的根本常识和开发技巧。在实践使用中,能够依据需求对爬虫进行定制化开发,完成更丰厚的功用。祝你在爬虫范畴获得更好的成果!
相关
-
r言语事例剖析,R言语在金融数据剖析中的运用事例剖析详细阅读

R言语是一种功用强壮的核算剖析和图形表明东西,广泛运用于数据剖析和数据可视化。以下是几个具体的R言语事例剖析,展现了其根本用法和实践运用:1.人口趋势剖析:事例布景:...
2025-01-07 1
-
c言语长整型,深化了解C言语中的长整型(long)详细阅读
在C言语中,长整型(longinteger)一般用于表明比规范整型(int)更大的整数。长整型在C言语中的类型名称是`long`。在大多数现代计算机体系中,`long`类...
2025-01-07 1
-
r言语在核算中的运用,从根底到高档剖析详细阅读

R言语在核算中的运用十分广泛,它是一种专门用于核算剖析、图形表明和陈述的编程言语和软件环境。以下是R言语在核算中的一些首要运用:1.数据处理和剖析:R言语供给了丰厚的数据操作...
2025-01-07 1
-
java获取本机ip, 运用`InetAddress.getLocalHost()`获取本机IP地址详细阅读

您的本机IP地址是`10.0.29.121`。Java获取本机IP地址的具体攻略在Java编程中,获取本机的IP地址是一个常见的需求,无论是进行网络编程仍是进行系统配置,了...
2025-01-07 1
-
c言语根号函数,二、sqrt()函数的界说与头文件详细阅读

在C言语中,根号函数一般指的是核算平方根的函数。C规范库中供给了`sqrt`函数,用于核算非负数的平方根。这个函数界说在`math.h`头文件中。下面是运用`sqrt`函数的一...
2025-01-07 0
-
rust好玩吗,探究末日的生计之旅,这款游戏终究好玩在哪里?详细阅读

Rust是一种相对较新的编程言语,由Mozilla基金会开发。它以其内存安全性和并发性而出名,一起供给了类似于C和C的功能。关于一些程序员来说,Rust的学...
2025-01-07 2
-
r言语导入excel数据, 运用内置函数导入Excel数据详细阅读

在R言语中,导入Excel数据一般运用`readxl`包。这个包供给了`read_excel`函数,能够方便地读取Excel文件。以下是一个根本的示例,展现了怎么运用`read...
2025-01-07 0
-
r言语正则表达式,二、R言语正则表达式根底详细阅读

R言语中的正则表达式功用十分强壮,常用于文本处理和形式匹配。以下是R言语中一些常用的正则表达式操作:1.`grepl`函数:用于在字符串中查找形式。假如找到了形式,它将回来...
2025-01-07 1
-
go是什么,什么是Go言语?详细阅读

Go言语(一般称为Golang)是一种静态类型的、编译型的编程言语,由Google开发,并于2009年初次发布。Go言语的规划旨在简化编程进程,进步开发功率,一起坚持程序的可...
2025-01-07 0
-
r言语删去列,R言语中删去数据框(dataframe)列的有用办法详细阅读

在R言语中,删去数据框(dataframe)中的列有多种办法。以下是几种常见的办法:1.运用`subset`函数:```R假定df是您的数据框,您想要删去名为...
2025-01-07 1