
python大数据结构,技术优势与运用场景
1. Apache Hadoop:Hadoop是一个开源的分布式核算结构,首要用于处理大规模数据集。它由两个首要组件组成:Hadoop Distributed File System 和 MapReduce。HDFS是一个分布式文件体系,用于存储很多数据,而MapReduce是一种编程模型,用于处理这些数据。
2. Apache Spark:Spark是一个快速、通用的大数据处理引擎,它支撑多种数据处理方式,包含批处理、流处理、交互式查询和机器学习。Spark以其快速的核算才能和灵敏的编程模型而出名。
3. Apache Flink:Flink是一个开源的流处理结构,它支撑事情驱动运用程序,能够实时处理数据流。Flink还支撑批处理,因而它能够作为Spark的替代品。
4. Apache Kafka:Kafka是一个分布式流处理渠道,它用于构建实时的数据管道和流运用程序。Kafka能够处理高吞吐量的数据流,而且具有高可用性和可扩展性。
5. Apache HBase:HBase是一个开源的非联系型数据库,它根据Google的Bigtable模型。HBase适用于存储非结构化数据,如文本、图画和视频。
6. Apache Hive:Hive是一个数据仓库东西,它根据Hadoop生态体系。Hive答运用户运用HiveQL(类似于SQL的查询言语)来查询存储在HDFS中的数据。
7. Apache Storm:Storm是一个开源的实时流处理结构,它答运用户处理实时的数据流。Storm以其简略易用的编程模型而出名。
8. Apache Cassandra:Cassandra是一个开源的分布式NoSQL数据库,它规划用于处理很多数据,并具有高可用性和可扩展性。
9. Apache Drill:Drill是一个开源的分布式查询引擎,它支撑多种数据源,包含HDFS、HBase、Cassandra等。Drill答运用户运用SQL查询这些数据源。
10. Apache NiFi:NiFi是一个开源的数据流办理东西,它答运用户规划、布置和办理数据流。NiFi具有图形化的用户界面,使得数据流的创建和办理变得简略。
这些结构和东西各自具有不同的特色和优势,挑选适宜的东西取决于详细的运用场景和需求。
深化解析Python大数据结构:技术优势与运用场景

跟着大数据年代的到来,数据处理和剖析的需求日益增长。Python作为一种功用强大、易于学习的编程言语,在数据处理和大数据剖析范畴得到了广泛运用。本文将深化解析Python大数据结构,讨论其技术优势和运用场景。
一、Python大数据结构概述
Python大数据结构首要包含以下几种:
PySpark:根据Apache Spark的Python API,用于大规模数据处理和剖析。
Pandas:供给高性能、易用的数据结构和数据剖析东西。
Numpy:供给高性能的多维数组目标和东西,用于科学核算。
Scikit-learn:供给机器学习算法和东西,用于数据发掘和猜测。
二、PySpark:Apache Spark的Python API

PySpark是Apache Spark的Python API,它答运用户运用Python编写Spark运用程序。PySpark具有以下特色:
分布式核算:PySpark能够在集群环境中进行分布式核算,充分使用集群的核算资源。
易于运用:PySpark供给了丰厚的API,使得用户能够轻松地编写Spark运用程序。
丰厚的算法:PySpark内置了多种机器学习算法,如分类、回归、聚类等。
三、Pandas:数据处理与剖析利器
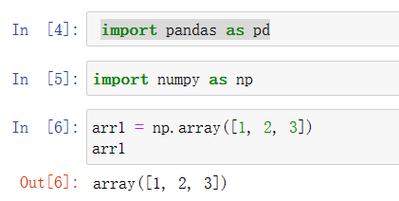
Pandas是一个开源的Python库,供给高性能、易用的数据结构和数据剖析东西。Pandas具有以下特色:
数据结构:Pandas供给了多种数据结构,如DataFrame、Series等,便使用户进行数据处理。
数据剖析:Pandas供给了丰厚的数据剖析功用,如数据清洗、数据转化、数据聚合等。
可视化:Pandas能够与matplotlib、seaborn等可视化库结合,便使用户进行数据可视化。
四、Numpy:科学核算根底

Numpy是一个开源的Python库,供给高性能的多维数组目标和东西,用于科学核算。Numpy具有以下特色:
多维数组:Numpy供给了多维数组目标,便使用户进行科学核算。
数学函数:Numpy内置了丰厚的数学函数,如三角函数、指数函数等。
线性代数:Numpy供给了线性代数运算功用,如矩阵运算、求解线性方程组等。
五、Scikit-learn:机器学习算法与东西
Scikit-learn是一个开源的Python库,供给机器学习算法和东西。Scikit-learn具有以下特色:
算法丰厚:Scikit-learn供给了多种机器学习算法,如分类、回归、聚类等。
易于运用:Scikit-learn供给了简略的API,便使用户进行机器学习。
可视化:Scikit-learn能够与matplotlib、seaborn等可视化库结合,便使用户进行数据可视化。
六、Python大数据结构运用场景
Python大数据结构在各个范畴都有广泛的运用,以下罗列几个典型运用场景:
金融职业:使用Python大数据结构进行危险评价、信誉评分、出资组合优化等。
医疗职业:使用Python大数据结构进行疾病猜测、药物研制、医疗数据剖析等。
电商职业:使用Python大数据结构进行用户画像、引荐体系、广告投进等。
交际网络:使用Python大数据结构进行用户行为剖析、交际网络剖析等。
Python大数据结构在数据处理和剖析范畴具有广泛的运用远景。经过深化解析Python大数据结构,咱们能够更好地了解其技术优势和运用场景,为实践项目供给有力支撑。
相关
-
大数据的最主要特征是,大数据的主要特征详细阅读

大数据一般具有以下几个主要特征,这些特征被称为“大数据的4V”:1.数据量(Volume):大数据的一个明显特征是其规划巨大。它触及的数据量一般到达GB、TB乃至PB等级,远...
2025-01-07 0
-
数据库可疑,深化解析数据库可疑问题及解决方案详细阅读

“数据库可疑”或许是指数据库存在以下几种状况:1.数据走漏:数据库中的灵敏信息或许被未经授权的人员拜访或盗取,导致数据走漏。2.SQL注入进犯:进犯者经过在数据库查询中刺进...
2025-01-07 1
-
大数据与云核算联络,协同开展的未来趋势详细阅读

大数据与云核算是两个密切相关但又不完全相同的概念。大数据(BigData)是指数据规划巨大、类型多样、增加速度快、处理难度高的数据调集。大数据的特色是“4V”,即Volume...
2025-01-07 2
-
大数据中心是干什么的,数字年代的中心根底设备详细阅读

大数据中心是一个专门用于存储、处理和剖析很多数据的设备。它一般包含多个服务器、存储设备和网络设备,以及相应的软件和东西,用于支撑数据办理、数据剖析和数据发掘等使命。大数据中心的...
2025-01-07 1
-
数据库新建表,从根底到实践详细阅读

创立一个新表一般需求以下几个进程:1.确认表名和字段名:首要,需求确认新表的称号以及该表需求包含的字段称号。2.确认字段类型:关于每个字段,需求确认其数据类型,例如整数、字...
2025-01-07 0
-
江苏省大数据办理局,引领数字经济展开新篇章详细阅读

江苏省大数据办理局,也称江苏省数据局(江苏省政务服务办理办公室),是江苏省内担任数据办理和政务服务的重要安排。以下是关于该安排的详细信息:功能1.遵循落实方针:担任遵循落实...
2025-01-07 0
-
mysql怎样用,MySQL 简介详细阅读

1.装置MySQL:假如你还没有装置MySQL,你需求从官方网站下载并装置它。装置完结后,你能够在指令行中输入`mysqlurootp`来登录...
2025-01-07 1
-
mysql免暗码登录,MySQL 免暗码登录装备攻略详细阅读

MySQL免暗码登录一般不是引荐的做法,由于它会带来严峻的安全危险。假如你是在一个彻底受信赖的环境中,例如在开发环境中,而且你了解这种做法的潜在危险,那么你能够依照以下过程进行...
2025-01-07 1
-
unique数据库,什么是Unique索引?详细阅读

在数据库中,`UNIQUE`束缚是一种重要的机制,用于保证表中特定列或列组合的值是仅有的,然后避免数据重复。以下是关于`UNIQUE`束缚的具体解说:1.界说和效果:...
2025-01-07 0
-
创立一个数据库,创立数据库的sql句子代码详细阅读
创立一个数据库一般触及以下几个进程:1.确认数据库类型:首要,您需求决议运用哪种类型的数据库,如联系型数据库(如MySQL、PostgreSQL)或非联系型数据库(如Mong...
2025-01-07 1