
r言语做相关性剖析,办法、实践与解读
在R言语中,进行相关性剖析一般运用`cor`函数。这个函数能够核算两个变量之间的相联系数,如皮尔逊相联系数、斯皮尔曼等级相联系数或肯德尔等级相联系数。下面我将具体介绍怎么运用`cor`函数进行相关性剖析。
过程1:装置和加载必要的包首要,保证你现已装置了R言语。假如你还没有装置,你能够从R的官方网站下载并装置。
过程2:预备数据你需求预备你的数据集,一般是一个数据框(data frame)或矩阵(matrix)。保证你的数据没有缺失值,因为`cor`函数在核算相联系数时会扫除缺失值。
过程3:运用`cor`函数运用`cor`函数时,你能够指定不同的参数来核算不同类型的相联系数。下面是一些常见的参数:
`x`:第一个变量或矩阵。 `y`:第二个变量或矩阵(假如`x`是矩阵,则`y`有必要是一个向量)。 `method`:核算相联系数的办法,默以为pearson,其他选项包括pearson、spearman和kendall。 `use`:怎么处理缺失值,默以为everything,其他选项包括all.obs(扫除任何包括缺失值的调查值)和pairwise.complete.obs(只考虑彻底调查到的对)。
示例假定咱们有一个数据框`data`,其间包括两个变量`x`和`y`。咱们想要核算这两个变量之间的皮尔逊相联系数。
```R 假定数据框如下data 核算皮尔逊相联系数correlation 这个示例会输出两个变量之间的皮尔逊相联系数。
注意事项 在进行相关性剖析之前,保证你的数据是数值型的。 相关性剖析只能提醒变量之间的联系,不能证明因果联系。 在解说相联系数时,考虑数据的规模和散布,以及或许的异常值。
假如你有具体的数据集或问题,请供给具体信息,我能够协助你进行更具体的相关性剖析。
R言语进行相关性剖析:办法、实践与解读
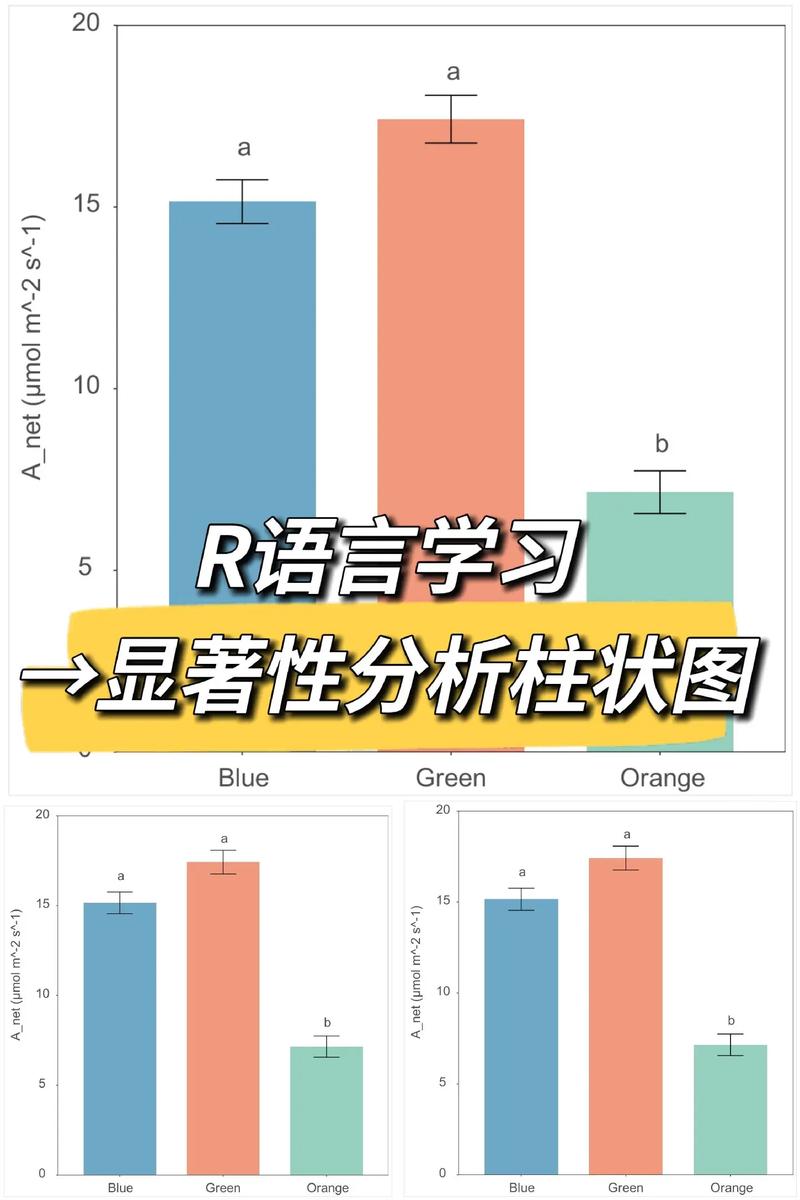
在数据剖析范畴,相关性剖析是研讨变量之间联系的重要手法。R言语作为一种强壮的核算软件,供给了丰厚的东西和办法来进行相关性剖析。本文将具体介绍R言语进行相关性剖析的办法、实践过程以及成果解读。
一、R言语简介
R言语是一种专门用于核算核算和图形表明的编程言语。因为其开源、免费的特色,R言语在学术界和工业界得到了广泛的运用。R言语具有丰厚的包和函数,能够方便地进行各种核算剖析。
二、相关性剖析概述
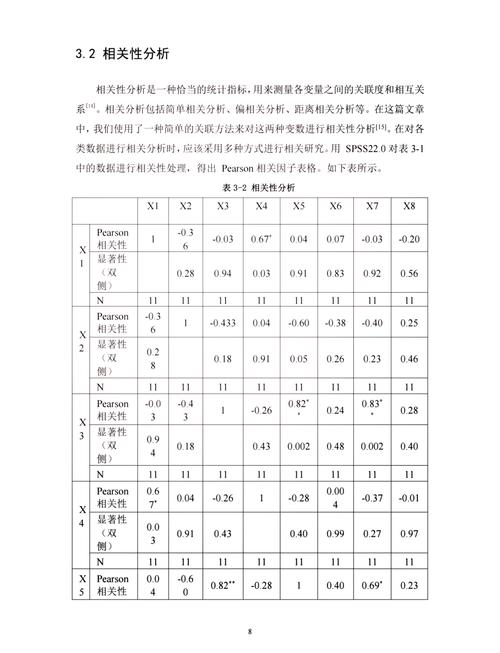
相关性剖析旨在研讨两个或多个变量之间的线性联系。常用的相关性系数有皮尔逊相联系数、斯皮尔曼秩相联系数和肯德尔秩相联系数等。皮尔逊相联系数适用于连续变量,而斯皮尔曼和肯德尔秩相联系数适用于有序分类变量。
三、R言语进行相关性剖析的办法
1. 运用cor函数核算相联系数
cor函数是R言语中核算相联系数的根本函数。以下是一个示例代码,用于核算两个变量之间的皮尔逊相联系数:
```R
加载数据
data <- read.csv(\
相关
-
python怎样另起一行, 运用换行符 `\详细阅读
在Python中,你能够运用不同的办法来另起一行。以下是几种常见的办法:1.运用反斜杠()作为行连接符,但在下一行的最初必须有一个空格或制表符。```pythonline1...
2025-01-08 0
-
python列表删去元素, 删去单个元素详细阅读

以下是运用不同办法删去列表中的元素后的成果:1.运用`remove`办法删去列表中的第一个匹配项后,列表变为:2.运用`pop`办法删去索引为1的元素后,列表变为...
2025-01-08 0
-
java衔接mysql,Java衔接MySQL数据库详解详细阅读

Java衔接MySQL数据库一般涉及到以下几个过程:1.增加MySQLJDBC驱动:保证你的项目中现已包含了MySQL的JDBC驱动。假如你运用的是Maven或Gradle...
2025-01-08 0
-
python意思,python意思中文翻译详细阅读
python在中文里是一个音译词,它指的是一种编程言语。Python是一种解说型、面向对象、动态数据类型的高档程序规划言语。它由GuidovanRossum在19...
2025-01-08 1
-
rust资源点详细阅读

关于《Rust》游戏中的资源点信息,我整理了一些详细的资源点攻略和视频教程,期望对你有所协助:1.《rust腐蚀》各个资源点详细解说刷卡教程/绿卡/红卡/蓝卡:视频教...
2025-01-08 0
-
123go详细阅读

“123go”通常是指一个简略的指令或提示,用于发动某个活动、游戏或使命。它类似于“开端”或“动身”的意思,常用于激起人们开端举动。在详细的上下文中,“123go”能够指代不同...
2025-01-08 0
-
c言语pow函数,运用方法、留意事项与常见过错详细阅读
`pow`函数是C言语中的一个数学函数,用于核算x的y次幂,即x^y。它是`math.h`头文件中界说的一个函数,原型如下:```cdoublepow;`...
2025-01-08 2
-
php怎样装置,PHP环境建立与装置攻略详细阅读

Windows1.下载PHP装置包:你能够从PHP官网下载Windows版别的装置包。2.运转装置包并依照提示完结装置。3.装备环境变量:将PHP的装置途径增加到体系环...
2025-01-08 1
-
pascal命名法,什么是Pascal命名法?详细阅读

Pascal命名法(PascalCase)是一种常见的命名约好,用于编程和软件开发中。在这种命名法中,每个单词的首字母都大写,单词之间没有空格或分隔符。例如:`thisIsA...
2025-01-08 1
-
php一句话木马详细阅读

深化解析PHP一句话木马:原理、结构与绕过WAF一、PHP一句话木马的界说与原理PHP一句话木马,望文生义,便是一段只要一行代码的木马程序。它经过在方针网站中刺进一段PHP代码...
2025-01-08 1