
大数据面试题,大数据面试题全解析,助你轻松应对面试应战
1. 请简述大数据的界说及其重要性。 答复示例: 大数据是指规划巨大、类型多样、处理速度快的数据调集。大数据的重要性在于它能够协助企业、政府和个人更好地了解复杂问题,做出更正确的决议计划,进步功率和生产力。
2. 请解说Hadoop生态体系中的首要组件及其效果。 答复示例: Hadoop生态体系包括HDFS(Hadoop Distributed File System)、MapReduce、YARN(Yet Another Resource Negotiator)、Hive、HBase、Pig、Sqoop、Flume等组件。HDFS用于存储大数据,MapReduce用于处理大数据,YARN用于资源办理,Hive用于数据仓库,HBase用于实时数据拜访,Pig用于数据处理,Sqoop用于数据导入/导出,Flume用于数据收集。
3. 请解说什么是数据发掘,以及它在大数据中的使用。 答复示例: 数据发掘是从很多数据中提取有价值信息的进程。在大数据中,数据发掘能够协助发现躲藏的方式、趋势和相关,从而为商业决议计划、市场营销、危险办理等供给支撑。
4. 请简述Spark与Hadoop MapReduce的差异。 答复示例: Spark是一个快速、通用的核算引擎,支撑内存核算,供给多种API(如Scala、Java、Python、R)。Hadoop MapReduce是一个依据磁盘的核算结构,首要用于批处理。Spark比Hadoop MapReduce更快,由于它是依据内存的,而且供给了更丰厚的API。
5. 请解说什么是数据仓库,以及它在大数据中的使用。 答复示例: 数据仓库是一个会集存储很多数据的体系,用于支撑数据剖析和陈述。在大数据中,数据仓库能够存储来自多个来历的数据,并供给一个一致的数据视图,以便进行数据剖析和陈述。
6. 请简述什么是机器学习,以及它在大数据中的使用。 答复示例: 机器学习是一种让核算机主动学习和改善的技能。在大数据中,机器学习能够用于猜测剖析、引荐体系、图像识别、自然言语处理等。
7. 请解说什么是数据办理,以及它在大数据中的使用。 答复示例: 数据办理是指办理数据质量、数据安全、数据隐私等问题的进程。在大数据中,数据办理能够协助确保数据的质量和安全性,恪守相关法规和政策。
8. 请简述什么是数据湖,以及它在大数据中的使用。 答复示例: 数据湖是一个存储原始、未加工数据的体系,用于支撑大数据剖析和机器学习。在大数据中,数据湖能够存储来自多个来历的数据,并供给一个灵敏、可扩展的数据存储解决方案。
9. 请解说什么是数据可视化,以及它在大数据中的使用。 答复示例: 数据可视化是将数据转换为图形、图表等视觉方式的进程。在大数据中,数据可视化能够协助用户更直观地了解数据,发现数据中的方式和趋势。
10. 请简述什么是数据安全,以及它在大数据中的使用。 答复示例: 数据安满是指维护数据免受未授权拜访、走漏、篡改等要挟的进程。在大数据中,数据安满是十分重要的,由于大数据一般包括灵敏和重要的信息。
这些面试题仅仅大数据范畴的一小部分。在实践面试中,面试官可能会依据你的布景和经历提出更详细的问题。因而,在预备面试时,最好了解大数据范畴的最新趋势和技能,以及相关的实践使用事例。
大数据面试题全解析,助你轻松应对面试应战

跟着大数据技能的快速开展,越来越多的企业开端注重大数据人才的培育。大数据面试题成为了求职者进入心仪企业的重要关卡。本文将为您全面解析大数据面试题,助您轻松应对面试应战。
一、大数据基础知识

1. 什么是大数据?
大数据是指数据量十分巨大、多样化、高速增加、难以处理的数据。它具有4个特征:很多(Volume)、多样(Variety)、快速(Velocity)和价值(Value)。
2. 大数据技能的特色是什么?
大数据技能具有以下特色:
分布式存储:如HDFS、HBase等。
分布式核算:如MapReduce、Spark等。
实时处理:如Storm、Flink等。
数据发掘与剖析:如Hive、Pig等。
二、Hadoop生态圈
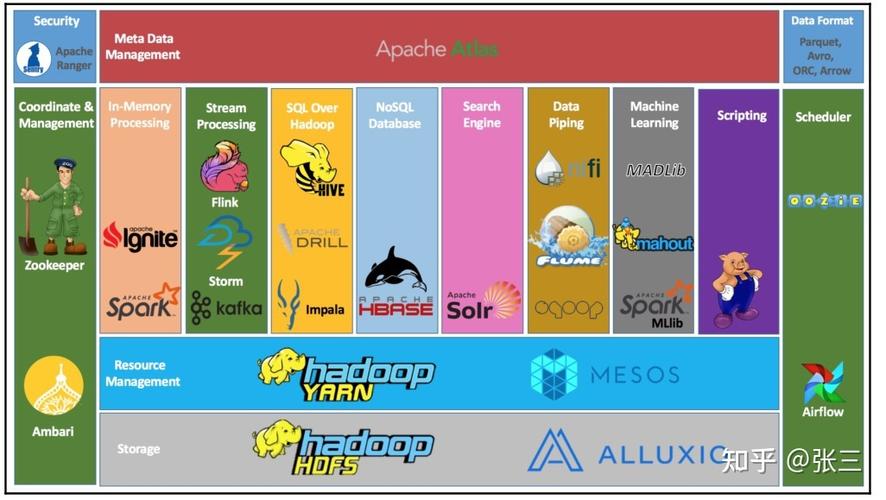
1. 什么是Hadoop?
Hadoop是一个开源的分布式核算结构,用于存储和处理大规划数据集。
2. Hadoop的中心组件是什么?
Hadoop的架构能够划分为两个首要部分:HDFS和MapReduce。
HDFS:分布式文件体系,担任存储数据。
MapReduce:分布式核算结构,担任处理数据。
三、Spark技能栈
1. 什么是Spark?
Spark是一个开源的分布式核算体系,用于大规划数据处理。它具有以下特色:
速度快:Spark的运转速度比Hadoop快100倍。
通用性:Spark支撑多种编程言语,如Java、Scala、Python等。
易用性:Spark供给了丰厚的API和东西,便利用户进行数据处理。
2. Spark的中心组件有哪些?
Spark Core:Spark的中心组件,供给分布式核算结构。
Spark SQL:Spark的SQL接口,用于处理结构化数据。
Spark Streaming:Spark的实时数据处理组件。
MLlib:Spark的机器学习库。
四、Kafka
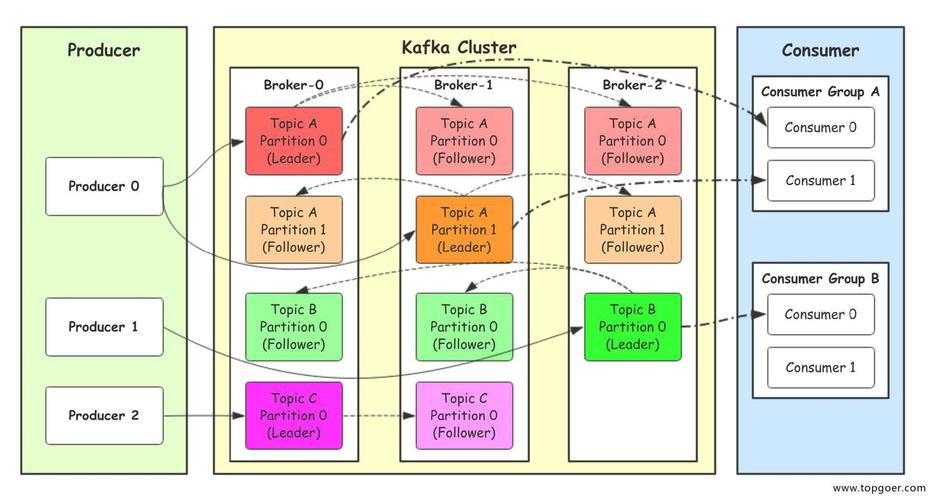
1. 什么是Kafka?
Kafka是一个开源的分布式流处理借题发挥,用于构建实时数据管道和流使用程序。
2. Kafka的首要特色有哪些?
高吞吐量:Kafka能够处理高吞吐量的数据。
可扩展性:Kafka能够水平扩展,以习惯不断增加的数据量。
持久性:Kafka能够确保数据的持久性,即便在体系故障的情况下也不会丢掉数据。
五、HBase
1. 什么是HBase?
HBase是一个分布式、可扩展的NoSQL数据库,建立在HDFS之上。
2. HBase的首要特色有哪些?
高吞吐量:HBase能够处理高吞吐量的数据。
可扩展性:HBase能够水平扩展,以习惯不断增加的数据量。
强一致性:HBase确保数据的强一致性。
六、数据仓库与数据湖
1. 什么是数据仓库?
数据仓库是一个用于存储、办理和剖析很多数据的体系。
2. 什么是数据湖?
数据湖是一个用于存储原始数据的体系,它不依赖于特定的数据格式或结构。
七、必备SQL题与算法题

1. SQL题
编写一个SQL查询,计算每个部分职工的均匀薪资。
编写一个SQL查询,找出销售额最高的前10个产品。
2. 算法题
完成一个快速排序算法。
完成一个二分查找算法。
大数据面试题
相关
-
大数据范畴专家,大数据范畴的开展趋势与应战详细阅读

我国大数据范畴闻名人物1.马云阿里巴巴集团创始人、董事局主席。马云是大数据年代的先知,早在2013年就呼吁大数据年代的到来,并在阿里巴巴及其旗下阿里云平台上推进大数据使...
2025-01-10 0
-
mysql5,数据库界的经典之作,为何至今仍受喜欢?详细阅读

MySQL5是一个广泛运用的开源联系型数据库办理体系,它由MySQLAB公司开发,后来被甲骨文公司收买。MySQL5供给了强壮的数据存储和办理功用,支撑多种编程言...
2025-01-10 0
-
企业大数据剖析,敞开智能决议计划新时代详细阅读

企业大数据剖析是指使用大数据技能对企业内部和外部的海量数据进行搜集、存储、处理、剖析和发掘,以获取有价值的信息和洞悉,然后协助企业做出更正确的决议计划、优化业务流程、进步运营功...
2025-01-10 0
-
数据库书面考试,全面解析常见题型及应对战略详细阅读

数据库书面考试题因为我没有详细的书面考试标题,我将供给一些常见的数据库书面考试题型和考点,协助你预备书面考试。常见题型:选择题:调查数据库根底常识,例如数据模型、联系代数...
2025-01-10 0
-
数据库redis详细阅读

Redis是一个开源的运用ANSIC编写的键值对存储数据库。它支撑多种类型的数据结构,如字符串(strings)、散列(hashes)、列表(lists)、调集(set...
2025-01-10 0
-
oracle表重命名,Oracle数据库中表重命名的操作攻略详细阅读

在Oracle数据库中,要重命名一个表,能够运用`RENAME`句子。以下是重命名表的语法:```sqlRENAMEold_table_nameTOnew_table_n...
2025-01-10 0
-
四川省大数据局详细阅读

四川省大数据局是四川省政府直属的综合性安排,担任和谐推进全省数据根底准则减少,统筹数据资源整合同享和开发利用,统筹推进“数字四川”、数字经济、数字社会规划和减少等作业。其主要功...
2025-01-10 0
-
数据库like,什么是LIKE操作符?详细阅读

在数据库中,`LIKE`是一个用于在`WHERE`子句中履行形式匹配的运算符。它一般与`%`(表明恣意数量的字符)和`_`(表明单个字符)通配符一同运用。下面是`L...
2025-01-10 0
-
数据库削减了数据冗余,数据库削减数据冗余的重要性与完成办法详细阅读
1.规范化和反规范化:经过将数据分解为多个相关表,每个表只包括一组相关数据,能够削减数据冗余。但过度规范化或许会导致查询功能下降,因而需求依据实践需求进行反规范化,即在保证数...
2025-01-10 1
-
数据库晋级,迈向高效、安全的数字化未来详细阅读

数据库晋级是一个触及多个进程的杂乱进程,旨在进步数据库的功用、安全性和功用。以下是进行数据库晋级的一般进程:1.需求剖析:确认晋级的意图,例如进步功用、添加功用、增强...
2025-01-10 0