
大数据剖析结构,大数据剖析结构概述
1. Hadoop:Hadoop 是一个开源的大数据处理结构,由 Apache 软件基金会保护。它运用 MapReduce 编程模型来处理大规模数据集,并运用 HDFS(Hadoop Distributed File System)来存储数据。
2. Spark:Spark 是一个快速、通用的大数据处理引擎,由 Apache 软件基金会保护。它支撑多种编程言语(如 Scala、Java、Python 等)和多种数据处理场景(如批处理、流处理、机器学习等)。
3. Flink:Flink 是一个开源的流处理结构,由 Apache 软件基金会保护。它支撑事情驱动和实时数据处理,并具有容错性和可扩展性。
4. Hive:Hive 是一个构建在 Hadoop 之上的数据仓库东西,由 Apache 软件基金会保护。它供给了一个相似 SQL 的查询言语(HiveQL)来查询和剖析存储在 HDFS 中的数据。
5. Impala:Impala 是一个开源的、依据内存的 SQL 查询引擎,由 Cloudera 开发。它可以直接在 HDFS 或 HBase 上履行 SQL 查询,并具有低推迟和高功能的特色。
6. Presto:Presto 是一个开源的、分布式的大数据处理结构,由 Facebook 开发。它支撑多种数据源(如 HDFS、Cassandra、MySQL 等)和多种查询言语(如 SQL、JDBC 等)。
7. Druid:Druid 是一个开源的、实时剖析数据存储,由 Metamarkets 开发。它支撑实时数据摄入、快速查询和可扩展性,常用于构建实时剖析运用。
8. Elasticsearch:Elasticsearch 是一个开源的、分布式的查找和剖析引擎,由 Elastic 开发。它支撑全文查找、索引和剖析,并具有高可用性和可扩展性。
9. Kafka:Kafka 是一个开源的、分布式的流处理渠道,由 Apache 软件基金会保护。它支撑高吞吐量、可扩展性和容错性的数据流处理。
10. TensorFlow:TensorFlow 是一个开源的机器学习结构,由 Google 开发。它支撑大规模的机器学习模型练习和推理,并具有可扩展性和灵活性。
这些结构可以依据不同的需求和场景进行挑选和运用,以应对大数据环境下的应战。
大数据剖析结构概述
大数据剖析结构的分类
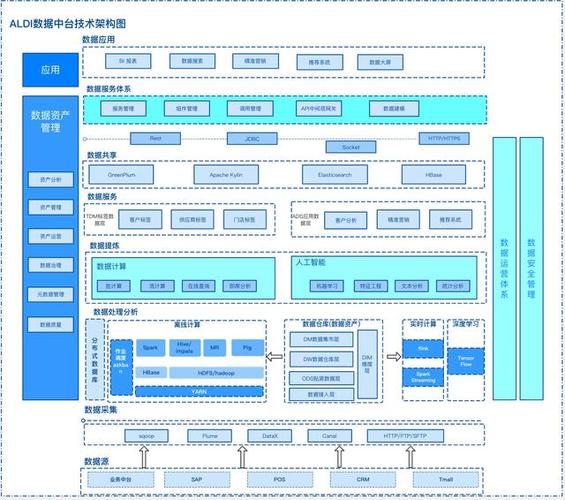
依据不同的运用场景和需求,大数据剖析结构可以分为以下几类:
分布式文件体系:如Hadoop的HDFS、Alluxio等,担任存储海量数据。
分布式核算结构:如Hadoop的MapReduce、Spark、Flink等,担任对数据进行分布式核算。
数据处理和剖析东西:如Hive、Pig、Impala等,供给SQL查询接口,便利用户进行数据处理和剖析。
实时核算结构:如Apache Storm、Apache Flink、Apache Spark Streaming等,担任实时处理和剖析数据流。
机器学习结构:如TensorFlow、PyTorch、Apache Mahout等,供给机器学习算法和模型练习功用。
干流大数据剖析结构介绍
以下介绍几种干流的大数据剖析结构:
Hadoop
Hadoop是一个开源的分布式核算结构,由Apache软件基金会开发。它包含HDFS(分布式文件体系)和MapReduce(分布式核算模型)两个中心组件。Hadoop可以高效地处理和剖析大规模数据集,广泛运用于互联网、金融、医疗、教育等范畴。
Spark
Spark是一个快速、通用的大数据处理引擎,它供给了高档API(如Spark SQL、Spark Streaming、MLlib和GraphX)和用于构建大规模数据处理运用程序的分布式核算模型。Spark在内存中处理数据,比较Hadoop的MapReduce,具有更高的功能和更低的推迟。
Flink
Flink是一个开源的分布式流处理结构,由Apache软件基金会开发。Flink支撑批处理和流处理,具有高功能、低推迟、容错性强等特色。Flink广泛运用于实时数据处理、机器学习、杂乱事情处理等范畴。
Storm
Storm是由Twitter开源的一个分布式实时核算体系,用于处理大规模数据流。Storm具有高吞吐量、低推迟、容错性强等特色,广泛运用于实时数据处理、实时剖析、实时引荐等范畴。
大数据剖析结构的挑选与优化
依据实践需求挑选适宜的结构:不同的结构具有不同的特色和优势,应依据实践需求挑选适宜的结构。
优化数据存储和核算资源:合理装备数据存储和核算资源,进步数据处理和剖析功率。
重视结构的生态圈:挑选具有丰厚生态圈的结构,便利获取相关东西和资源。
重视结构的社区活跃度:挑选社区活跃度高的结构,便于获取技术支撑和解决方案。
大数据剖析结构是支撑大数据剖析的中心技术,关于进步数据处理和剖析功率具有重要意义。了解和把握干流的大数据剖析结构,有助于更好地应对大数据年代的应战。在挑选和优化大数据剖析结构时,应依据实践需求、资源情况和社区活跃度等要素进行归纳考虑。
相关
-
大数据四大特征,大数据的四大特征详细阅读

大数据的四大特征一般被称为“4V”,即:1.Volume(数据量):大数据的一个明显特征是数据量巨大,无论是结构化数据还对错结构化数据,其规划都远远超出了传统数据处理才能。2...
2025-01-15 0
-
数据库达观锁和失望锁,原理、运用与差异详细阅读

达观锁与失望锁:两种不同的并发操控战略在数据库中,达观锁和失望锁是两种常用的并发操控战略,用于处理多线程环境下数据共同性问题。它们的首要差异在于对数据抵触的处理办法:失望锁...
2025-01-15 0
-
物业大数据,敞开才智物业新时代详细阅读

物业大数据在物业办理中的使用非常广泛,它不仅能够进步物业办理功率,还能优化服务流程,增强企业的竞争力。以下是关于物业大数据的详细信息:1.物业大数据的界说和渠道:物业...
2025-01-15 0
-
mysql建数据库,MySQL数据库的创立与装备攻略详细阅读

创立MySQL数据库一般包括以下几个过程:1.衔接到MySQL服务器。2.创立数据库。3.创立表(可选)。4.刺进数据(可选)。5.查询数据(可选)。以下是创立MyS...
2025-01-15 0
-
数据库图标,数据库图标的界说与重要性详细阅读

1.数据库办理体系图标:通常是一个相似硬盘的图标,有时会带有数据库的标志,如SQLServer的图标是一个带有“S”的硬盘,Oracle的图标是一个带有“O”的圆形。2....
2025-01-15 0
-
access数据库运用教程,Access数据库运用教程——从入门到通晓详细阅读

假如你想学习Access数据库的运用,能够参阅以下几种资源:1.菜鸟教程:网站供给了具体的Access数据库教程,包含根底操作和高档运用。你能够经过拜访获取更多信息。...
2025-01-15 0
-
sqlite和mysql差异,深化解析两种数据库办理体系的差异详细阅读

SQLite和MySQL是两种不同的数据库办理体系,它们在架构、运用场景、功用、功用等方面存在一些差异。以下是它们之间的一些首要差异:1.架构:SQLite是...
2025-01-15 0
-
文档数据库有哪些,怎么自己做一个数据库供自己查询详细阅读

1.MongoDB:可能是最著名的文档数据库之一,它运用BSON(一种二进制表明的JSON)作为其数据存储格局。MongoDB供给了强壮的查询言语和索引功用,适用于处理很多数...
2025-01-15 0
-
壮熊数据库,构建熊职业信息宝库详细阅读
1.BearVideo数据库:BearVideo是一个私家保藏的数据库,供给多种查找和阅读方法,包含主页、查找、随机、图表、列表、Top10等。2.下载壮熊数据库:...
2025-01-15 0
-
附加数据库失利,原因剖析与解决方法详细阅读

1.数据库文件途径问题:请保证您供给的数据库文件途径是正确的,而且该文件是可拜访的。2.数据库文件格局问题:请保证您测验附加的数据库文件格局与您的数据库办理体系兼容。3....
2025-01-15 0