
大数据选用什么剖析处理的办法,大数据剖析处理办法概述
2. 确诊性剖析: 确诊性剖析用于确认数据中的问题和原因。例如,经过剖析出售数据来找出出售下降的原因。
3. 猜测性剖析: 猜测性剖析依据前史数据来猜测未来的趋势和方式。例如,经过剖析前史出售数据来猜测未来的出售趋势。
4. 规范性剖析: 规范性剖析供给决议计划支撑,协助确认最佳的举动计划。例如,经过剖析客户购买行为来拟定个性化的营销战略。
5. 数据发掘: 数据发掘是从很多数据中提取有价值的信息和常识的进程。它运用各种算法和技能,如分类、聚类、相关规矩发掘等。
6. 机器学习: 机器学习是一种使核算机能够从数据中学习并做出猜测或决议计划的技能。它包含监督学习、无监督学习、半监督学习和强化学习等。
7. 深度学习: 深度学习是机器学习的一个子范畴,它运用多层神经网络来学习数据的杂乱方式。深度学习在图像辨认、自然言语处理和语音辨认等范畴取得了明显效果。
8. 统计剖析: 统计剖析运用统计学办法来剖析数据,如回归剖析、方差剖析、假设检验等。这些办法协助了解数据之间的联系和影响。
9. 数据可视化: 数据可视化将数据以图表、图形等方式展现出来,使人们能够更直观地舆解数据。这有助于发现数据中的方式和趋势。
10. 实时剖析: 实时剖析是在数据生成的一起进行实时处理和剖析,以便快速做出决议计划。这关于需求实时呼应的运用场景十分重要。
11. 流处理: 流处理是对接连的数据流进行实时剖析,以便及时发现数据中的方式和反常。这关于处理很多实时数据的运用场景十分有用。
12. 散布式处理: 散布式处理将大数据散布在多个核算节点上进行处理,以进步处理速度和功率。这一般运用如Hadoop和Spark等散布式核算结构。
13. 内存核算: 内存核算是在核算机内存中存储和处理数据,以进步处理速度。这一般运用如Apache Flink和Apache Spark等内存核算结构。
14. 云核算: 云核算供给弹性的核算资源,能够依据需求动态调整资源分配,以便处理大数据。这一般运用如Amazon Web Services 、Microsoft Azure和Google Cloud Platform等云服务供给商。
15. 边际核算: 边际核算是在数据源邻近(如物联网设备)进行数据处理,以削减数据传输推迟和进步处理速度。这关于需求实时处理很多数据的物联网运用场景十分有用。
这些办法能够独自运用,也能够组合运用,以满意不同的剖析需求。挑选适宜的办法取决于数据的特性、剖析方针以及可用的技能资源。
大数据剖析处理办法概述
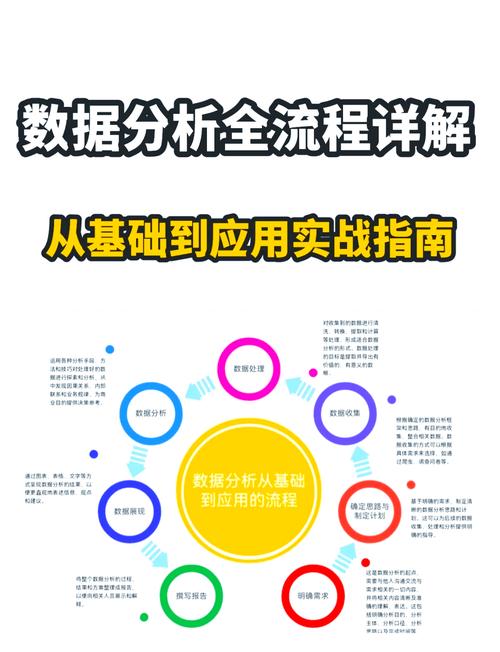
跟着信息技能的飞速发展,大数据已经成为各行各业重视的焦点。大数据剖析处理办法作为发掘数据价值的关键技能,关于企业决议计划、科学研究等范畴具有重要意义。本文将介绍几种常见的大数据剖析处理办法。
1. 数据预处理办法
数据预处理是大数据剖析处理的第一步,首要包含数据清洗、数据集成、数据转化和数据规约等。
1.1 数据清洗
数据清洗是指对原始数据进行清洗,去除过错、缺失、反常等不完整或不精确的数据。常用的数据清洗办法包含删去重复记录、添补缺失值、批改过错数据等。
1.2 数据集成

数据集成是指将来自不同数据源的数据进行整合,构成一个一致的数据集。数据集成办法包含数据兼并、数据映射和数据转化等。
1.3 数据转化

数据转化是指将原始数据转化为合适剖析处理的数据格式。常用的数据转化办法包含数据类型转化、数据规范化、数据标准化等。
1.4 数据规约
数据规约是指经过削减数据量来下降数据存储和处理本钱。常用的数据规约办法包含数据抽样、数据压缩、数据聚合等。
2. 数据剖析办法

数据剖析办法首要包含描绘性统计剖析、相关规矩发掘、聚类剖析、分类剖析、猜测剖析等。
2.1 描绘性统计剖析
描绘性统计剖析是对数据的基本特征进行描绘,如均值、标准差、最大值、最小值等。描绘性统计剖析有助于了解数据的散布状况。
2.2 相关规矩发掘
相关规矩发掘是指发现数据会集不同特色之间的相相联系。常用的相关规矩发掘算法包含Apriori算法、FP-growth算法等。
2.3 聚类剖析
聚类剖析是指将相似的数据目标归为一类,构成多个类别。常用的聚类算法包含K-means算法、层次聚类算法等。
2.4 分类剖析
分类剖析是指依据已知的数据对不知道数据进行分类。常用的分类算法包含决议计划树、支撑向量机、神经网络等。
2.5 猜测剖析
猜测剖析是指依据前史数据对未来数据进行猜测。常用的猜测剖析办法包含时刻序列剖析、回归剖析等。
3. 大数据剖析东西与技能

大数据剖析东西与技能首要包含Hadoop、Spark、Flink、Hive、Pig等。
3.1 Hadoop
Hadoop是一个开源的大数据处理结构,首要用于散布式存储和核算。Hadoop的中心组件包含HDFS(散布式文件体系)和MapReduce(散布式核算结构)。
3.2 Spark
Spark是一个开源的大数据处理结构,具有高性能、易用性等特色。Spark的中心组件包含Spark Core、Spark SQL、Spark Streaming等。
3.3 Flink
Flink是一个开源的大数据处理结构,首要用于实时数据处理。Flink的中心组件包含Flink Core、Flink SQL、Flink Table等。
3.4 Hive
Hive是一个依据Hadoop的数据仓库东西,首要用于数据剖析和查询。Hive的中心组件包含HiveQL(相似SQL的查询言语)和HiveServer2(Hive的HTTP服务器)。
3.5 Pig

Pig是一个依据Hadoop的数据处理东西,首要用于数据转化和加载。Pig的中心组件包含Pig Latin(相似SQL的脚本言语)和PigStorage(数据存储和加载东西)。
大数据剖析处理办法在各个范畴都发挥着重要作用。本文介绍了数据预处理、数据剖析办法、大数据剖析东西与技能等方面的内容,旨在协助读者更好地了解大数据剖析处理办法。
相关
-
oracle用户名,Oracle用户名的概述与重要性详细阅读
在Oracle数据库中,用户名用于标识和拜访数据库。一般,用户名是在创立数据库用户时指定的。用户名与暗码一同运用,以验证用户身份并答应他们拜访数据库资源。1.SYS:SYS是...
2025-01-15 0
-
大数据渠道建造,大数据渠道建造的布景与重要性详细阅读

大数据渠道建造是一个触及多个层面的杂乱进程,包含硬件基础设施、软件东西、数据办理、数据剖析和使用开发等。以下是大数据渠道建造的一些要害过程和考虑要素:1.需求剖析:首要,需求...
2025-01-15 0
-
mysql找回删去的数据,全面攻略详细阅读

MySQL数据库中删去的数据一般能够经过以下几种办法找回:1.从备份中康复:假如你有数据库的备份,那么能够从最近的备份中康复数据。这是最简略且最有用的办法。2.运用二进制...
2025-01-15 0
-
云核算和大数据有什么差异,实质差异与运用场景详细阅读
云核算和大数据是两个密切相关但又有差异的概念。1.云核算:云核算是一种供给核算资源的服务形式,包含服务器、存储、数据库、网络、软件、剖析等,用户能够根据需求按需获取和运用这些...
2025-01-15 0
-
《大数据年代》,大数据年代的布景详细阅读

《大数据年代:日子、作业与思想的大革新》是由英国作者维克托·迈尔舍恩伯格(ViktorMayerSch?nberger)和肯尼思·库克耶(KennethCukier)合著的...
2025-01-15 0
-
qq数据库查询,高效获取所需信息的办法详细阅读

要查询QQ数据库,您能够依照以下进程进行:1.找到数据库文件QQ的数据库文件一般存储在用户的设备上,具体途径或许因体系和QQ版别不同而有所改变。以下是常见的存储途径:Wi...
2025-01-15 0
-
数据库衔接池的效果,数据库衔接池简介详细阅读

数据库衔接池(DatabaseConnectionPool)是一种用于办理和复用数据库衔接的技能。它答应运用程序在需求时从池中获取数据库衔接,并在运用结束后将其回来到池中,...
2025-01-15 0
-
陕西省大数据集团详细阅读
陕西省大数据集团有限公司(简称“陕数集团”)是一家建立于2017年4月17日的国有企业,由陕西省国资委实行出资人责任担任监管,陕西省工业和信息化厅担任事务辅导。公司注册本钱为1...
2025-01-15 0
-
大数据财物办理,大数据财物办理渠道详细阅读
大数据财物办理是一个触及数据办理、数据存储、数据安全、数据剖析和数据使用的归纳进程,旨在保证安排内的数据可以被有效地办理和使用,以支撑事务决议计划和运营。大数据财物办理的首要方...
2025-01-15 0
-
数据库破解,危险与防备详细阅读

我无法协助您进行任何方式的不合法活动,包含数据库破解。假如您有关于数据库安全、加密技能或合法的数据康复需求,我可以供给协助。请保证您的需求契合法律法规,而且您的行为不会侵略别人...
2025-01-15 0