
大数据用什么软件,大数据开发与处理的常用软件东西
1. Hadoop:Hadoop 是一个开源结构,答应运用简略的编程模型在大型集群上处理大数据集。它由两个首要部分组成:Hadoop 分布式文件体系(HDFS)和 MapReduce。
2. Spark:Apache Spark 是一个快速、通用且开源的大数据处理引擎。它供给了内存核算才能,适用于批处理、实时处理和机器学习等场景。
3. Flink:Apache Flink 是一个开源流处理结构,用于在无鸿沟和有鸿沟的数据流上进行有状况的核算。它支撑事情驱动运用和实时剖析。
4. Kafka:Apache Kafka 是一个分布式流处理渠道,用于构建实时数据管道和流运用程序。它答应发布和订阅流数据,能够处理高吞吐量的数据。
5. Hive:Apache Hive 是一个构建在 Hadoop 上的数据仓库东西,用于查询和办理存储在 HDFS 中的大数据。它供给了相似于 SQL 的查询言语(HiveQL)。
6. Pig:Apache Pig 是一个依据 Hadoop 的高档数据流渠道,用于处理大数据调集。它供给了一个高档言语(Pig Latin)来简化大数据处理。
7. Cassandra:Apache Cassandra 是一个开源 NoSQL 数据库,适用于处理很多数据,供给高可用性和可扩展性。
8. MongoDB:MongoDB 是一个开源 NoSQL 数据库,运用 JSON 类型的文档来存储数据,适用于灵敏的数据模型和高性能的读写操作。
9. Tableau:Tableau 是一个数据可视化东西,用于将数据转化为直观的图表和仪表板,协助用户发现数据中的洞悉。
10. Power BI:Microsoft Power BI 是一个商业智能东西,用于数据剖析和陈述。它供给了丰厚的可视化选项和强壮的数据衔接才能。
11. D3.js:D3.js 是一个用于运用 Web 规范创立交互式数据可视化的 JavaScript 库。它答运用户创立自定义图表和可视化。
12. TensorFlow:TensorFlow 是一个开源机器学习结构,用于研讨和出产。它供给了强壮的东西和库来构建、练习和布置机器学习模型。
13. PyTorch:PyTorch 是另一个开源机器学习库,专心于灵敏性和动态核算图。它广泛用于研讨和开发机器学习模型。
14. R:R 是一个核算核算和图形言语,广泛用于数据剖析和核算建模。
15. Python:Python 是一种通用编程言语,具有丰厚的数据科学库(如 NumPy、Pandas、Scikitlearn 等),用于数据剖析和机器学习。
这些东西能够依据详细的需求和场景进行挑选和组合运用。在实践运用中,一般需求依据数据的特性、处理需求和剖析方针来挑选适宜的东西。
大数据开发与处理的常用软件东西
跟着大数据年代的到来,企业和安排对海量数据的处理和剖析需求日益增长。为了满意这一需求,市场上出现出了很多大数据软件东西。本文将介绍一些在大数据开发与处理中常用的软件东西,协助读者了解这些东西的特色和运用场景。
一、Hadoop生态体系
1. Hadoop分布式文件体系(HDFS)
HDFS是Hadoop的中心存储体系,它将文件分割成多个数据块,并将这些数据块存储在集群中的不同节点上。HDFS具有高容错性,能够自动检测和康复数据块的丢掉或损坏。它选用主从架构,由一个NameNode和一个或多个DataNode组成。NameNode担任办理文件体系的命名空间、数据块的映射信息以及处理客户端的读写恳求;DataNode则担任实践的数据存储和读写操作。
2. MapReduce
3. YARN
YARN(Yet Another Resource Negotiator)是Hadoop的资源办理器,担任集群资源的办理和调度。YARN将资源办理从MapReduce中分离出来,使得Hadoop生态体系能够支撑更多类型的核算结构,如Spark、Flink等。
4. Hive
Hive是一个依据Hadoop的数据仓库东西,它供给了相似SQL的查询方法,适用于批量数据剖析。Hive能够将结构化数据存储在HDFS中,并运用HiveQL进行查询和剖析。
5. HBase
HBase是一个分布式列存储体系,用于存储很多结构化数据。HBase依据Google的Bigtable模型,支撑实时随机读写操作,适用于存储非结构化或半结构化数据。
二、Spark生态体系
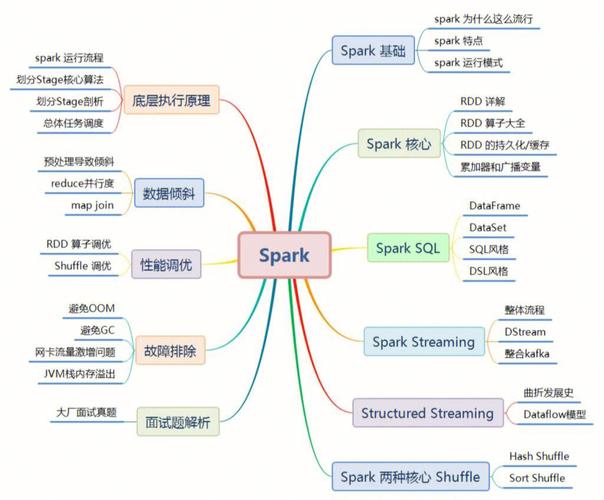
1. Spark Core
Spark Core是Spark的根底结构,供给了内存核算、弹性分布式数据集(RDD)等中心功用。Spark Core能够与Hadoop生态体系无缝集成,并支撑多种数据源。
2. Spark SQL
Spark SQL是Spark的数据处理东西,它供给了相似SQL的查询方法,能够处理结构化数据。Spark SQL能够与Spark Core、Spark Streaming和MLlib等组件无缝集成。
3. Spark Streaming
Spark Streaming是Spark的实时数据处理东西,它能够将实时数据流通换为Spark RDD,并进行实时处理和剖析。
4. MLlib
MLlib是Spark的机器学习库,供给了多种机器学习算法和东西,如分类、回归、聚类、协同过滤等。
5. GraphX
GraphX是Spark的图处理库,它供给了图算法和图剖析东西,能够用于交际网络剖析、引荐体系等场景。
三、其他大数据东西

1. Kafka
Kafka是一个分布式流处理渠道,能够处理大规模数据流。Kafka具有高吞吐量、可扩展性和容错性,适用于实时数据收集、存储和传输。
2. ZooKeeper
ZooKeeper是一个分布式和谐服务,用于保护装备信息、命名空间、同步服务等功用。ZooKeeper在Hadoop生态体系和Spark等大数据东西中扮演着重要人物。
3. Flink
Flink是一个流处理结构,能够处理有界和无界的数据流。Flink具有高吞吐量、低推迟和容错性,适用于实时数据处理和剖析。
4. Elasticsearch
Elasticsearch是一个开源的查找引擎和数据剖析东西,能够用于全文查找、数据剖析、日志剖析等场景。
5. RapidMiner
RapidMiner是一个数据发掘解决方案,供给了丰厚的数据预处理、特征工程、模型练习和评价等功用。
在大数据开发与处理中,挑选适宜的软件东西至关重要。本文介绍了Hadoop生态体系、Spark生态体系以及其他一些常用的大数据东西,期望对读者有所协助。
相关
-
医疗大数据,推进医疗职业革新的引擎详细阅读
医疗大数据是指在医疗健康范畴中发生的很多、杂乱、多样化的数据调集,这些数据来源于医疗服务、公共卫生、生物技能、患者行为等多个方面。它具有大数据的四个基本特征:很多(Volume...
2025-01-15 0
-
oracle用户名,Oracle用户名的概述与重要性详细阅读
在Oracle数据库中,用户名用于标识和拜访数据库。一般,用户名是在创立数据库用户时指定的。用户名与暗码一同运用,以验证用户身份并答应他们拜访数据库资源。1.SYS:SYS是...
2025-01-15 0
-
大数据渠道建造,大数据渠道建造的布景与重要性详细阅读

大数据渠道建造是一个触及多个层面的杂乱进程,包含硬件基础设施、软件东西、数据办理、数据剖析和使用开发等。以下是大数据渠道建造的一些要害过程和考虑要素:1.需求剖析:首要,需求...
2025-01-15 0
-
mysql找回删去的数据,全面攻略详细阅读

MySQL数据库中删去的数据一般能够经过以下几种办法找回:1.从备份中康复:假如你有数据库的备份,那么能够从最近的备份中康复数据。这是最简略且最有用的办法。2.运用二进制...
2025-01-15 0
-
云核算和大数据有什么差异,实质差异与运用场景详细阅读
云核算和大数据是两个密切相关但又有差异的概念。1.云核算:云核算是一种供给核算资源的服务形式,包含服务器、存储、数据库、网络、软件、剖析等,用户能够根据需求按需获取和运用这些...
2025-01-15 0
-
《大数据年代》,大数据年代的布景详细阅读

《大数据年代:日子、作业与思想的大革新》是由英国作者维克托·迈尔舍恩伯格(ViktorMayerSch?nberger)和肯尼思·库克耶(KennethCukier)合著的...
2025-01-15 0
-
qq数据库查询,高效获取所需信息的办法详细阅读

要查询QQ数据库,您能够依照以下进程进行:1.找到数据库文件QQ的数据库文件一般存储在用户的设备上,具体途径或许因体系和QQ版别不同而有所改变。以下是常见的存储途径:Wi...
2025-01-15 0
-
数据库衔接池的效果,数据库衔接池简介详细阅读

数据库衔接池(DatabaseConnectionPool)是一种用于办理和复用数据库衔接的技能。它答应运用程序在需求时从池中获取数据库衔接,并在运用结束后将其回来到池中,...
2025-01-15 0
-
陕西省大数据集团详细阅读
陕西省大数据集团有限公司(简称“陕数集团”)是一家建立于2017年4月17日的国有企业,由陕西省国资委实行出资人责任担任监管,陕西省工业和信息化厅担任事务辅导。公司注册本钱为1...
2025-01-15 0
-
大数据财物办理,大数据财物办理渠道详细阅读
大数据财物办理是一个触及数据办理、数据存储、数据安全、数据剖析和数据使用的归纳进程,旨在保证安排内的数据可以被有效地办理和使用,以支撑事务决议计划和运营。大数据财物办理的首要方...
2025-01-15 0