
散布式联系型数据库有哪些, 什么是散布式联系型数据库?
散布式联系型数据库是指将数据散布在多个物理方位上,一起供给联系型数据库的功用,如业务支撑、数据一致性确保等。以下是几种常见的散布式联系型数据库:
1. Amazon Aurora:由AWS供给,是一种高可用性、高牢靠性的联系型数据库服务,能够主动扩展以处理更多的数据和作业负载。
2. Google Spanner:由Google供给,是一种全球散布式的联系型数据库,供给跨多个数据中心的业务处理才能。
3. CockroachDB:是一个开源的散布式联系型数据库,支撑跨多个数据中心的业务处理,并供给主动扩展和数据仿制功用。
4. YugabyteDB:是一个开源的、依据PostgreSQL的散布式联系型数据库,支撑跨多个数据中心的布置和业务处理。
5. TiDB:是一个开源的、依据Google Spanner和Facebook Pelican的散布式联系型数据库,供给跨多个数据中心的业务处理和数据仿制功用。
6. Citus:是一个开源的、依据PostgreSQL的散布式联系型数据库,支撑跨多个节点的数据散布和查询处理。
7. OceanBase:是一个由阿里巴巴开发的散布式联系型数据库,支撑高可用性、高牢靠性和跨多个数据中心的布置。
8. PolarDB:由阿里云供给,是一个依据MySQL的散布式联系型数据库,支撑主动扩展和数据仿制功用。
这些散布式联系型数据库在不同的场景下都有其共同的优势和运用,挑选适宜的数据库需求依据详细的需求和场景进行评价。
散布式联系型数据库:技能解析与运用场景
什么是散布式联系型数据库?
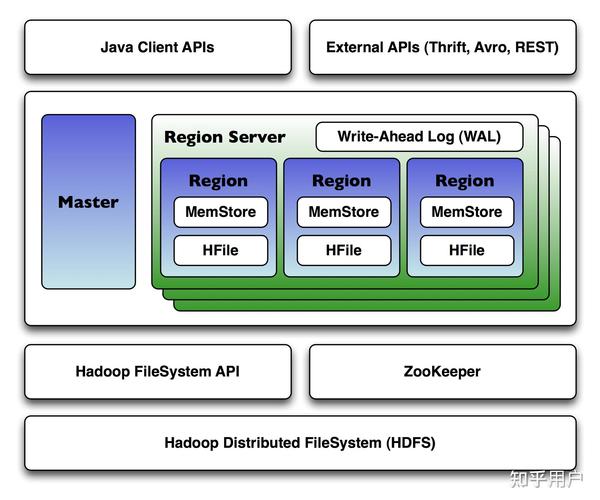
散布式联系型数据库是一种依据散布式架构的联系型数据库体系。它经过将数据涣散存储在多个节点上,完成了数据的横向扩展,然后进步了体系的处理才能和可用性。这种数据库体系在确保数据一致性和业务完整性的一起,还能满意大规模数据存储和高速查询的需求。
散布式联系型数据库的特色
散布式联系型数据库具有以下特色:
水平扩展:经过添加节点来进步体系处理才能。
强一致性:确保数据在散布式环境下的强一致性。
高可用性:经过数据冗余和毛病搬运机制,确保体系的高可用性。
兼容MySQL:运用与MySQL兼容的协议和语法,便利搬迁和开发。
实时HTAP:支撑在线业务处理和在线剖析处理,满意多种业务需求。
干流散布式联系型数据库介绍
1. TiDB
由PingCAP公司开源的一款散布式联系型数据库,支撑水平扩展、强一致性和高可用性。TiDB兼容MySQL协议,能够无缝代替MySQL,特别合适处理大规模数据的场景。
2. OceanBase
由蚂蚁金服开发的高功能散布式联系型数据库,支撑高并发和大规模数据存储。OceanBase适用于金融、电商、物流等需求高功能、高牢靠的场景。
3. GaussDB
华为自主立异研制的散布式联系型数据库,具有企业级杂乱业务混合负载才能,一起支撑散布式业务、同城跨AZ布置、数据0丢掉等功用。GaussDB适用于政务、金融、电商、O2O、电信CRM/计费等高扩展、弹性扩缩的运用场景。
散布式联系型数据库的运用场景
散布式联系型数据库适用于以下场景:
大规模数据存储和查询:如电商、金融、物联网等场景。
高并发业务场景:如交际网络、在线游戏等。
需求高可用性的业务场景:如政务、金融等。
需求实时剖析的场景:如实时监控、实时引荐等。
散布式联系型数据库的优势
散布式联系型数据库具有以下优势:
进步体系功能:经过水平扩展,进步体系处理才能和响应速度。
确保数据一致性:经过散布式一致性协议,确保数据在散布式环境下的强一致性。
进步体系可用性:经过数据冗余和毛病搬运机制,进步体系的高可用性。
下降运维本钱:经过主动化运维东西,下降运维本钱。
散布式联系型数据库在确保数据一致性和业务完整性的一起,还能满意大规模数据存储和高速查询的需求。跟着大数据和云核算的快速开展,散布式联系型数据库将在更多场景中得到运用。
相关
-
国网大数据,赋能动力互联网,推进才智动力展开详细阅读

国家电网有限公司大数据中心是国家电网公司的直属单位,成立于2019年3月,并于同年5月21日正式挂牌。该中心按分公司形式运营,是国家电网数字化转型的专业支撑组织,旨在服务国家大...
2025-01-24 1
-
大数据剖析的要害,界说与重要性详细阅读

大数据剖析的要害要素包含以下几个方面:1.数据搜集:首要需求搜集很多的数据,这些数据或许来自不同的来历,如交际媒体、物联网设备、企业内部体系等。数据搜集的准确性、完整性和及时...
2025-01-24 1
-
hana数据库,助力基因组研讨的新里程碑详细阅读
SAPHANA(全称SAPHighperformanceANalyticAppliance)是由SAP开发的一款高性能剖析东西,它将数据存储在内存中,而不是传统的硬盘上...
2025-01-24 1
-
我国工业企业数据库,经济研讨的重要东西详细阅读
我国工业企业数据库是由国家计算局树立的一个微观数据库,首要计算我国大陆区域年出售额500万元以上(2011年起为2000万元以上)的工业企业。这些企业包含国有企业、集体企业、股...
2025-01-24 1
-
高校大数据实验室,培育未来数据科学家的摇篮详细阅读

1.厦门大学数据库实验室研讨方向:厦门大学数据库实验室在大数据课程建造方面有明显奉献,编著了《大数据技能原理与使用》等13本大数据系列教材,被国内1000多所高校选用...
2025-01-24 1
-
oracle账号,Oracle账号注册与运用指南详细阅读

要在Oracle官网创立账号,您能够依照以下过程进行操作:1.准备工作:保证您有一个安稳的网络连接和一个有用的电子邮箱,由于注册过程中需求经过邮箱验证。2.拜访Or...
2025-01-24 1
-
代谢组学数据库,生物信息学的重要东西详细阅读

1.HMDB(HumanMetabolomeDatabase):专心于人类代谢组,供给了关于小分子代谢物的具体化学、生物化学和生理数据。包含代谢物的化学结...
2025-01-24 1
-
华住数据库被黑,揭秘黑客进犯与信息安全缝隙详细阅读

华住集团的数据走漏事情引起了广泛重视。以下是事情的详细情况:1.事情布景:2018年8月28日,有音讯称华住集团旗下酒店的用户数据在暗网出售。数据包含华住官网注册材料...
2025-01-24 1
-
大数据查找,大数据查找的鼓起与应战详细阅读

大数据(BigData)是指规划巨大、类型杂乱多样,在获取、存储、办理、剖析方面大大超出了传统数据库软件东西才能规模的数据调集。它具有5个首要特点,即很多(Volume)、高...
2025-01-24 1
-
我国年鉴全文数据库,全面体系反映国情资讯的信息资源库详细阅读

我国年鉴全文数据库,简称CYFD,是我国最大的接连更新的动态年鉴资源全文数据库。以下是该数据库的一些主要特色和使用指南:主要特色1.内容掩盖广泛:该数据库包含了基本国情、地...
2025-01-24 1