
分布式机器学习,大数据年代的处理方案
分布式机器学习是指使用多台核算机或处理器协同作业来履行机器学习使命的一种核算方法。它答应机器学习模型在更大的数据集上练习,并加快模型的练习进程。分布式机器学习一般涉及到以下几个要害方面:
1. 数据分发:在分布式环境中,数据一般被涣散存储在多个节点上。数据分发战略需求考虑怎么有用地将数据分配到各个节点上,以便并行处理。
2. 模型练习:分布式机器学习中的模型练习一般选用并行化技能,如数据并行或模型并行。数据并即将数据涣散到多个节点上,每个节点独立练习模型的一部分,然后将成果兼并。模型并行则将模型的不同部分分配到不同的节点上,每个节点担任练习模型的一部分。
3. 参数同步:在分布式练习进程中,各个节点需求定时同步模型的参数,以保证模型的练习一致性。参数同步战略需求平衡通讯开支和核算开支,以优化全体练习功能。
4. 负载均衡:分布式机器学习体系需求考虑怎么合理分配核算使命和数据,以完结负载均衡。负载均衡战略能够保证各个节点的作业负载相对均衡,防止某些节点过载而其他节点闲暇。
5. 容错性:分布式体系需求具有容错才能,以应对节点毛病、网络毛病等异常情况。容错战略能够包含数据备份、使命重试、节点替换等。
6. 可扩展性:分布式机器学习体系需求具有杰出的可扩展性,以习惯不断添加的数据规划和核算需求。可扩展功能够经过添加节点数量、优化算法和体系架构等方法完结。
7. 资源办理:分布式机器学习体系需求有用办理核算资源,包含CPU、内存、磁盘等。资源办理战略能够包含资源分配、使命调度、资源监控等。
分布式机器学习在处理大规划数据集、前进练习速度、完结负载均衡和容错性等方面具有优势。它也面对一些应战,如通讯开支、同步推迟、节点毛病等。因而,规划高效的分布式机器学习体系需求归纳考虑多个要素,以完结最优的功能和可靠性。
分布式机器学习:大数据年代的处理方案
一、分布式机器学习的概念与优势
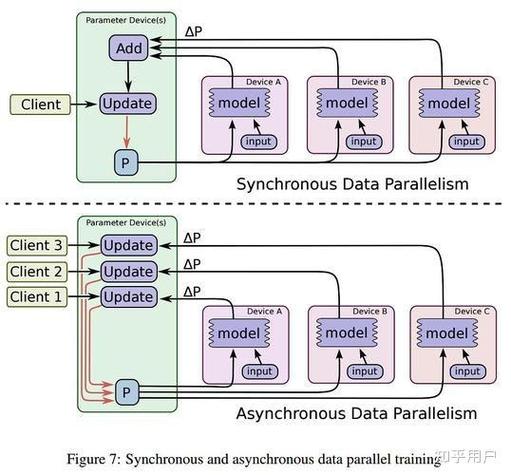
分布式机器学习是指将机器学习使命分解成多个子使命,在多个核算节点上并行履行,终究兼并成果以完结整个使命。这种形式具有以下优势:
前进核算功率:经过并行核算,分布式机器学习能够明显缩短核算时刻,满意实时性需求。
扩展性强:分布式机器学习能够轻松扩展到更多核算节点,习惯大规划数据集的处理。
容错性好:在分布式体系中,单个节点的毛病不会影响整个体系的运转,前进了体系的稳定性。
二、分布式机器学习结构
现在,分布式机器学习结构首要包含以下几种:
MapReduce编程模型:Hadoop MapReduce结构是典型的MapReduce编程模型,适用于大规划数据集的分布式核算。
Spark:Spark是一个开源的分布式核算体系,具有高效、易用、通用性强等特色,适用于各种分布式核算使命。
TensorFlow:TensorFlow是Google开发的开源机器学习结构,支撑分布式核算,适用于构建大规划机器学习模型。
三、分布式机器学习算法
分布式机器学习算法首要包含以下几种:
并行决策树:经过将决策树算法分解成多个子使命,在多个节点上并行练习,前进核算功率。
并行k-均值算法:将k-均值算法分解成多个子使命,在多个节点上并行履行,前进聚类功率。
四、分布式机器学习在实践中的使用
分布式机器学习在各个范畴都有广泛的使用,以下罗列几个典型使用场景:
金融范畴:分布式机器学习能够用于危险评价、诈骗检测、信誉评分等使命。
医疗健康范畴:分布式机器学习能够用于疾病猜测、药物研制、个性化医疗等使命。
零售范畴:分布式机器学习能够用于客户细分、需求猜测、库存办理等使命。
分布式机器学习是大数据年代处理杂乱核算问题的有用途径。跟着技能的不断发展,分布式机器学习将在更多范畴发挥重要作用,推进人工智能技能的前进。
相关
-
机器学习稳妥,机器学习在稳妥职业的使用与未来展望详细阅读

1.危险评价:机器学习技能能够协助稳妥公司对客户的危险进行评价,然后为他们供给更精确的稳妥费率。例如,经过剖析客户的人口统计数据、索赔前史、交际媒体活动等数据,创立猜...
2024-12-23 0
-
机器学习实战项目引荐,从理论到实践的桥梁详细阅读

1.房价猜测:运用前史房价数据来练习模型,猜测未来房价。这可以涉及到线性回归、决策树、随机森林等算法。2.情感剖析:剖析交际媒体上的文本,判别文本的情感倾向(正面、负面、中...
2024-12-23 0
-
ai生图软件,敞开构思无限的未来详细阅读

AI生图软件,一般指的是运用人工智能技能生成图画的软件。这类软件能够主动创立各种类型的图画,包含相片、艺术作品、规划图等。它们一般依据深度学习模型,如生成对立网络(GANs)或...
2024-12-23 0
-
吴恩达机器学习书,从入门到通晓的攻略详细阅读

吴恩达(AndrewNg)是闻名的机器学习专家,他撰写了多本机器学习相关书本,并供给了丰厚的学习资源。以下是他的一些首要书本和课程:1.《MachineLearning...
2024-12-23 0
-
机器学习 翻译,跨过言语障碍的智能桥梁详细阅读

机器学习(MachineLearning)是一种人工智能技能,它使核算机体系可以从数据中学习,并运用这些常识来做出决议计划或猜测。机器学习依赖于算法和核算模型,这些模型可以从...
2024-12-23 0
-
AI灯谱 器件归纳,立异照明解决计划的诞生详细阅读

AI灯谱器件是指那些可以经过人工智能技能进行光谱调理和智能操控的照明设备。以下是关于AI灯谱器件的一些要害信息和技能特色:1.AI灯谱调理:AI灯谱调理技能答使用户依...
2024-12-23 0
-
ai起名,立异与功率的完美结合详细阅读

当然能够!我能够协助你为你的AI项目起一个姓名。请告诉我一些关于你的项目的信息,比方它的功用、方针用户、或许你想要传达的主题。这样我能够更好地为你供给一个适宜的姓名。AI起名:...
2024-12-23 0
-
ai 归纳才干速写,立异与应战并存详细阅读

AI归纳才干速写是指经过AI技能快速捕捉和记载目标特征、动态和细节的一种艺术发明方法。它结合了人工智能的快速核算才干和艺术家的发明力,能够敏捷生成具有艺术美感的图画。这种技能...
2024-12-23 0
-
ai软件归纳实例,智能座舱与高中数学教育视频生成详细阅读

1.企业运用阿里巴巴:阿里巴巴运用人工智能进行客户购买猜测、产品描绘生成、才智城市建设和农业监测。例如,其“城市大脑”项目经过监控城市交通来缓解拥堵。苹果:苹果在iPh...
2024-12-23 0
-
归纳管线ai算法,才智城市建造的新引擎详细阅读

1.规划和规划:BIM模型使用AI主动完结管线装备:经过BIM(修建信息模型)技能,AI能够主动完结管线的装备,进步规划的合理性和精确度。2.安全:才智管廊...
2024-12-23 0