
大数据十大算法,十大不可或缺的数据发掘算法
大数据十大算法通常是指在大数据处理和剖析范畴中最为常用和有用的算法。这些算法协助从很大都据中提取有价值的信息,进行猜测、分类、聚类等使命。以下是大数据十大算法的扼要介绍:
1. 决议计划树算法:一种用于分类和回归使命的算法,经过构建树状结构来表明决议计划进程。2. 支撑向量机(SVM):一种用于分类和回归使命的算法,经过寻觅最优超平面来别离不同类别的数据。3. 随机森林算法:一种根据决议计划树的集成学习算法,经过构建多棵决议计划树并取均匀或大都投票来进步猜测准确性。4. k最近邻(kNN)算法:一种根据实例学习的分类算法,经过找到与待分类实例最类似的k个街坊并取大都投票来猜测类别。5. k均值聚类算法:一种无监督的聚类算法,经过将数据点分配到k个簇中心来构成簇。6. PageRank算法:一种用于网页排名的算法,经过剖析网页之间的链接联系来评价网页的重要性。7. Apriori算法:一种用于相关规矩发掘的算法,经过找出频频项集来生成相关规矩。8. FPgrowth算法:一种改善的相关规矩发掘算法,经过构建频频形式树来进步发掘功率。9. 聚类算法(如DBSCAN、层次聚类等):用于将数据点分组到不同的簇中,以便更好地了解和剖析数据。10. 时刻序列猜测算法(如ARIMA、SARIMA等):用于猜测时刻序列数据的未来趋势。
这些算法在大数据处理和剖析中发挥着重要作用,但并非一切算法都适用于一切场景。挑选适宜的算法取决于具体问题和数据特征。
大数据年代:十大不可或缺的数据发掘算法
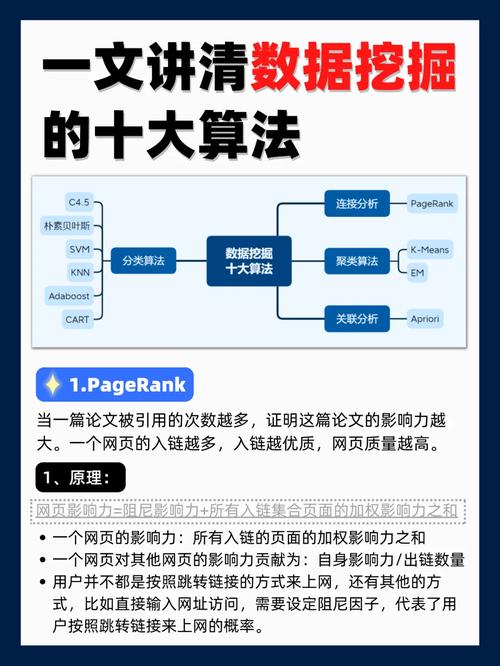
跟着大数据年代的到来,数据发掘技能成为了企业决议计划、科学研究和社会发展的重要东西。数据发掘算法作为数据发掘的中心,可以从海量数据中提取有价值的信息。本文将介绍大数据范畴十大经典的数据发掘算法,协助读者了解这些算法的基本原理和使用场景。
1. C4.5算法
C4.5算法是一种决议计划树算法,由Quinlan在1993年提出。它根据信息增益率来挑选割裂特点,可以处理接连和离散特点,并能处理具有缺失值的数据集。C4.5算法的长处是具有杰出的解说才能,可以生成易于了解的分类规矩。其缺陷是结构树的进程中,需求对数据集进行屡次的次序扫描和排序,导致算法的低效。
2. k-Means算法
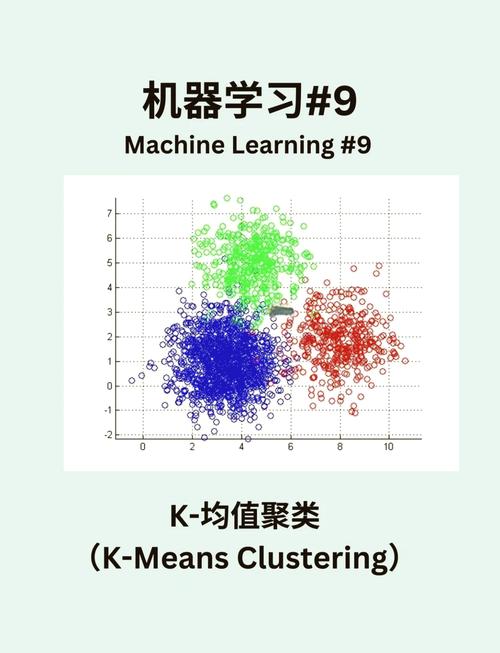
k-Means算法是一种无监督学习算法,用于将数据点划分为k个集群。它经过迭代更新每个集群的质心(即集群中一切点的均值)来作业。k-Means算法的长处是简略易完成,核算功率高。其缺陷是关于初始质心的挑选灵敏,且无法处理非球形聚类。
3. 支撑向量机(SVM)
SVM是一种根据监督学习的分类算法,其中心思维是找到一个超平面,使得不同类别的样本之间的间隔最大化。SVM可以有用地处理高维数据,并且在许多情况下对噪声和异常值具有较好的鲁棒性。SVM的长处是泛化才能强,可以处理非线性问题。其缺陷是核算杂乱度较高,关于大规模数据集或许不适用。
4. Apriori算法
Apriori算法是一种相关规矩发掘算法,用于发现数据会集的频频项集。Apriori算法经过逐层查找频频项集,并使用向下关闭性质来削减查找空间。Apriori算法的长处是可以发现数据中的相关规矩,适用于商场篮子剖析等场景。其缺陷是核算杂乱度较高,关于大规模数据集或许不适用。
5. 最大希望(EM)算法
EM算法是一种用于参数估计的迭代算法,常用于高斯混合模型(GMM)的参数估计。EM算法经过迭代求解希望(E)和最大化(M)两个过程来优化模型参数。EM算法的长处是可以处理杂乱的数据散布,适用于高斯混合模型等场景。其缺陷是关于初始参数的挑选灵敏,且或许堕入部分最优。
6. PageRank算法
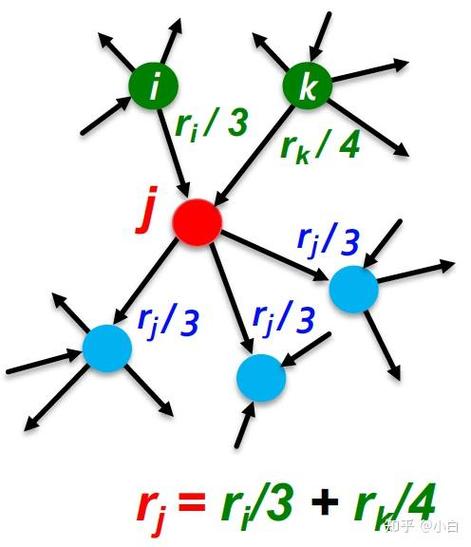
PageRank算法是一种用于网页排序的算法,由Google的创始人Page和Brin在1998年提出。PageRank算法经过核算网页之间的链接联系,对网页进行排序。PageRank算法的长处是可以发现网页之间的相关性,适用于查找引擎等场景。其缺陷是关于链接质量灵敏,且或许存在虚伪链接问题。
7. AdaBoost算法
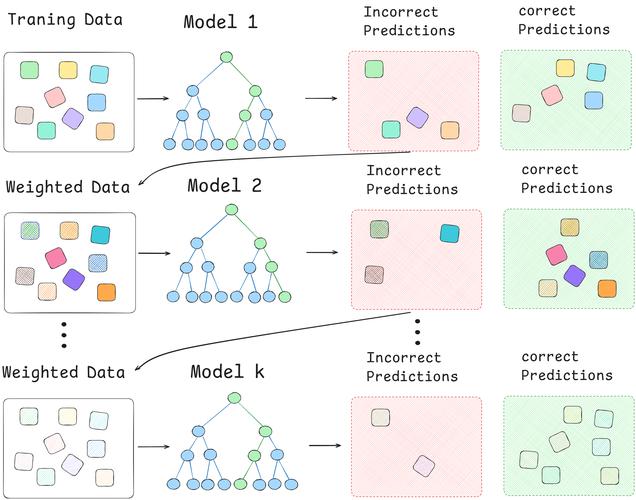
AdaBoost算法是一种集成学习方法,经过迭代练习多个弱分类器,并将它们组合成一个强分类器。AdaBoost算法的长处是可以进步分类器的准确率,适用于分类问题。其缺陷是关于噪声数据灵敏,且或许存在过拟合问题。
8. kNN算法
kNN算法是一种根据实例的学习算法,经过核算新数据点与练习会集最近k个数据点的间隔,来对新数据进行分类。kNN算法的长处是简略易完成,适用于小规模数据集。其缺陷是核算杂乱度较高,关于大规模数据集或许不适用。
9. Naive Bayes算法
Naive Bayes算法是一种根据贝叶斯定理的分类算法,适用于文本分类、垃圾邮件过滤等场景。Naive Bayes算法的长处是核算功率高,适用于大规模数据集。其缺陷是关于特征之间存在强相关性时,分类作用较差。
10. CART算法
CART算法是一种决议计划树算法,由Breiman等人于1984年提出。CART算法经过递归地挑选最优切割点来构建决议计划树。CART算法的长处是可以处理非线性问题,适用于回归和分类问题。其缺陷是关于噪声数据灵敏,且或许存在过拟合问题。
相关
-
博看人文热销期刊数据库,博看人文热销期刊数据库——全面掩盖人文范畴的数字阅览渠道详细阅读

博看人文热销期刊数据库是一个综合性的数字资源渠道,首要特点和功用如下:1.录入规模广泛:数据库录入了4000多种干流热销人文期刊,涵盖了党政、时势、军事、办理、财经、...
2025-02-26 2
-
互联网大数据人工智能,未来开展的三大引擎详细阅读

互联网大数据和人工智能是当时科技范畴的重要概念,它们之间既有差异也有严密的联络。以下是关于这两者的具体解说:互联网大数据互联网大数据是指经过互联网发生的海量数据。这些数据来源...
2025-02-26 2
-
mysql装置教程图解,MySQL装置教程图解详细阅读
以下是几篇具体的MySQL装置教程,包含图解进程,希望能协助你顺利完结MySQL的装置和装备:1.Mysql的装置和装备教程(超具体图文)从零根底入门到通晓链接:...
2025-02-26 5
-
大数据对社会的影响,大数据的兴起与界说详细阅读

1.经济领域:商业决议计划:企业使用大数据剖析消费者行为、商场趋势,优化产品和服务,进步营销效果。危险办理:金融机构经过大数据剖析来点评信用危险、商场危险,然...
2025-02-26 2
-
medline数据库,医学研讨的重要资源详细阅读
Medline数据库是美国国立医学图书馆(NationalLibraryofMedicine,NLM)创立和保护的世界性归纳生物医学信息书目数据库,是当时世界上最威望的...
2025-02-26 2
-
oracle衔接串,结构与运用详细阅读
深化解析Oracle衔接串:结构与运用Oracle数据库作为一款强壮的企业级数据库办理体系,在各个职业中得到了广泛的运用。在开发过程中,正确结构和运用Oracle衔接串关于数据...
2025-02-26 4
-
mysql二进制日志,功用、装备与运用场景详细阅读

MySQL的二进制日志(BinaryLog)是MySQL数据库中用于记载数据库中一切更改的一种日志记载办法。它记载了一切更改数据库数据的句子,但不记载SELECT、SHOW等...
2025-02-26 3
-
mysql乘法函数的运用方法,MySQL乘法函数的运用方法详解详细阅读

MySQL中的乘法函数主要是经过运用``运算符来完成的。你能够在查询中直接运用``来履行乘法运算。例如,假如你想核算两个数字的乘积,能够这样写:```sqlSELEC...
2025-02-26 4
-
wind金融数据库,金融数据服务的领军者详细阅读

深化解析Wind金融数据库:金融数据服务的领军者跟着金融商场的不断开展,金融数据服务在出资决议计划、危险办理、金融研讨等范畴扮演着越来越重要的人物。Wind金融数据库作为我国抢...
2025-02-26 2
-
大数据整理,重要性与应战详细阅读

1.数据质量查看:查看数据是否存在过错、不完整或格局不共同的状况。2.数据去重:辨认并删去重复的数据记载。3.数据转化:将数据转化为适宜剖析的格局,如将字符串转化为数值。...
2025-02-26 2