
大数据开源结构,大数据开源结构概述
1. Hadoop:Hadoop 是一个分布式核算结构,由 Apache 软件基金会开发。它包含 HDFS(Hadoop Distributed File System)和 MapReduce 两个首要组件。HDFS 用于存储大数据集,而 MapReduce 用于处理这些数据集。
2. Spark:Spark 是一个快速、通用且易于运用的分布式核算体系,由 Apache 软件基金会开发。它支撑多种编程言语,如 Scala、Java、Python 和 R。Spark 供给了多种数据处理功用,包含批处理、流处理、机器学习和图处理。
3. Flink:Flink 是一个开源流处理结构,由 Apache 软件基金会开发。它支撑批处理和流处理,而且具有高吞吐量和低推迟的特色。Flink 供给了丰厚的 API,支撑多种编程言语,如 Java、Scala 和 Python。
4. Kafka:Kafka 是一个分布式流处理渠道,由 Apache 软件基金会开发。它首要用于构建实时数据管道和流使用程序。Kafka 支撑高吞吐量、可扩展性和容错性,而且与多种大数据结构集成。
5. HBase:HBase 是一个分布式、可扩展的、面向列的存储体系,由 Apache 软件基金会开发。它依据 Hadoop 文件体系,供给了对大数据集的随机读写拜访。HBase 适用于需求快速随机拜访大数据集的使用程序。
6. Cassandra:Cassandra 是一个分布式 NoSQL 数据库,由 Apache 软件基金会开发。它具有高可用性、可扩展性和容错性,适用于处理大规模数据集。Cassandra 支撑多种编程言语,如 Java、Python 和 C。
7. Elasticsearch:Elasticsearch 是一个开源查找引擎,由 Elastic 公司开发。它依据 Lucene,供给了快速、精确的全文查找功用。Elasticsearch 适用于处理和剖析大规模文本数据集。
8. Storm:Storm 是一个实时流处理结构,由 Apache 软件基金会开发。它支撑高吞吐量和低推迟的流处理,而且具有容错性和可扩展性。Storm 供给了丰厚的 API,支撑多种编程言语,如 Java、Python 和 Ruby。
这些大数据开源结构在不同的使用场景中具有各自的优势和特色。依据实践需求,能够挑选适宜的结构来处理、存储和剖析大数据集。
大数据开源结构概述
1. Hadoop

Hadoop是由Apache基金会开发的一个开源分布式核算结构,首要用于存储和处理大规模数据集。它包含以下几个中心组件:
HDFS(Hadoop Distributed File System):分布式文件体系,用于存储海量数据。
MapReduce:分布式核算模型,用于处理大规模数据集。
Hive:数据仓库东西,供给相似SQL的查询接口。
HBase:列式存储数据库,适用于存储非结构化和半结构化数据。
Hadoop具有高牢靠性、高扩展性和高吞吐量等特色,适用于处理PB等级的数据。
2. Spark

Spark是Apache基金会开发的一个开源分布式核算引擎,它供给了快速、通用的大数据处理才能。Spark的中心组件包含:
Spark Core:Spark的根底组件,供给分布式使命调度、内存办理等功用。
Spark SQL:供给相似SQL的查询接口,支撑结构化数据存储和处理。
Spark Streaming:实时数据处理结构,支撑高吞吐量的数据流处理。
MLlib:机器学习库,供给多种机器学习算法。
GraphX:图处理结构,支撑大规模图数据的存储和处理。
Spark具有以下特色:
速度快:Spark的内存核算才能使其在处理大数据时比Hadoop快100倍以上。
通用性:Spark支撑多种数据处理场景,包含批处理、实时处理和机器学习。
易用性:Spark供给丰厚的API和东西,便利用户进行大数据开发。
3. Kafka
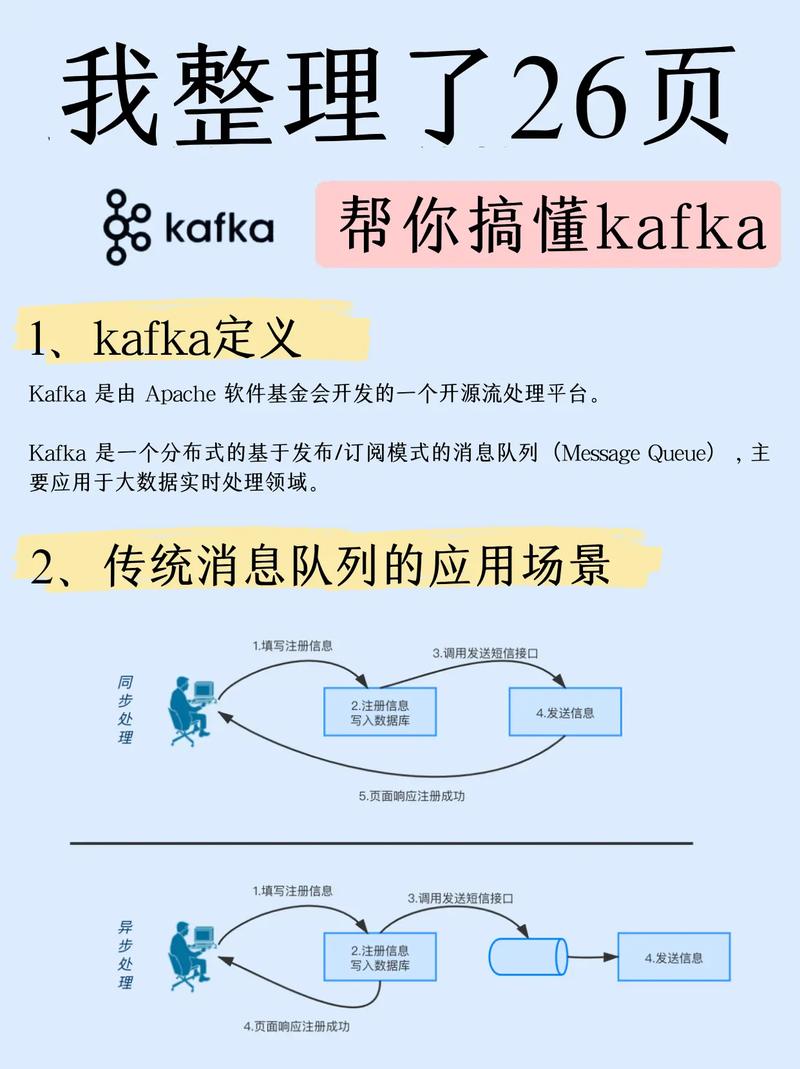
Kafka是由LinkedIn开发的一个开源流处理渠道,首要用于构建实时数据流处理体系。Kafka具有以下特色:
高吞吐量:Kafka能够处理高吞吐量的数据流,适用于处理PB等级的数据。
可扩展性:Kafka支撑水平扩展,能够轻松应对数据量的增加。
持久性:Kafka将数据存储在磁盘上,保证数据不会丢掉。
牢靠性:Kafka供给数据仿制和分区机制,保证数据传输的牢靠性。
Kafka广泛使用于日志搜集、实时剖析、事情源等场景。
4. Flink

Flink是由Apache基金会开发的一个开源流处理结构,它供给了高效、牢靠的流处理才能。Flink的中心组件包含:
流处理引擎:用于处理实时数据流。
批处理引擎:用于处理批量数据。
图处理引擎:用于处理大规模图数据。
Flink具有以下特色:
高性能:Flink的流处理引擎在处理实时数据流时具有高性能。
牢靠性:Flink供给数据备份和康复机制,保证数据处理的牢靠性。
易用性:Flink供给丰厚的API和东西,便利用户进行大数据开发。
大数据开源结构为处理和剖析海量数据供给了强壮的支撑。Hadoop、Spark、Kafka和Flink等结构各有特色,适用于不同的场景。用户能够依据实践需求挑选适宜的结构,以进步大数据处理功率。
相关
-
博看人文热销期刊数据库,博看人文热销期刊数据库——全面掩盖人文范畴的数字阅览渠道详细阅读

博看人文热销期刊数据库是一个综合性的数字资源渠道,首要特点和功用如下:1.录入规模广泛:数据库录入了4000多种干流热销人文期刊,涵盖了党政、时势、军事、办理、财经、...
2025-02-26 5
-
互联网大数据人工智能,未来开展的三大引擎详细阅读

互联网大数据和人工智能是当时科技范畴的重要概念,它们之间既有差异也有严密的联络。以下是关于这两者的具体解说:互联网大数据互联网大数据是指经过互联网发生的海量数据。这些数据来源...
2025-02-26 5
-
mysql装置教程图解,MySQL装置教程图解详细阅读
以下是几篇具体的MySQL装置教程,包含图解进程,希望能协助你顺利完结MySQL的装置和装备:1.Mysql的装置和装备教程(超具体图文)从零根底入门到通晓链接:...
2025-02-26 8
-
大数据对社会的影响,大数据的兴起与界说详细阅读

1.经济领域:商业决议计划:企业使用大数据剖析消费者行为、商场趋势,优化产品和服务,进步营销效果。危险办理:金融机构经过大数据剖析来点评信用危险、商场危险,然...
2025-02-26 4
-
medline数据库,医学研讨的重要资源详细阅读
Medline数据库是美国国立医学图书馆(NationalLibraryofMedicine,NLM)创立和保护的世界性归纳生物医学信息书目数据库,是当时世界上最威望的...
2025-02-26 5
-
oracle衔接串,结构与运用详细阅读
深化解析Oracle衔接串:结构与运用Oracle数据库作为一款强壮的企业级数据库办理体系,在各个职业中得到了广泛的运用。在开发过程中,正确结构和运用Oracle衔接串关于数据...
2025-02-26 7
-
mysql二进制日志,功用、装备与运用场景详细阅读

MySQL的二进制日志(BinaryLog)是MySQL数据库中用于记载数据库中一切更改的一种日志记载办法。它记载了一切更改数据库数据的句子,但不记载SELECT、SHOW等...
2025-02-26 7
-
mysql乘法函数的运用方法,MySQL乘法函数的运用方法详解详细阅读

MySQL中的乘法函数主要是经过运用``运算符来完成的。你能够在查询中直接运用``来履行乘法运算。例如,假如你想核算两个数字的乘积,能够这样写:```sqlSELEC...
2025-02-26 7
-
wind金融数据库,金融数据服务的领军者详细阅读

深化解析Wind金融数据库:金融数据服务的领军者跟着金融商场的不断开展,金融数据服务在出资决议计划、危险办理、金融研讨等范畴扮演着越来越重要的人物。Wind金融数据库作为我国抢...
2025-02-26 5
-
大数据整理,重要性与应战详细阅读

1.数据质量查看:查看数据是否存在过错、不完整或格局不共同的状况。2.数据去重:辨认并删去重复的数据记载。3.数据转化:将数据转化为适宜剖析的格局,如将字符串转化为数值。...
2025-02-26 5