
spark机器学习,Apache Spark简介
Apache Spark 是一个强壮的开源数据处理结构,它供给了丰厚的机器学习库,称为 MLlib。MLlib 支撑多种机器学习算法,包含分类、回归、聚类、协同过滤、决策树、随机森林和梯度进步树等。
以下是运用 Spark 进行机器学习的一些根本过程:
1. 数据预备:首要,需求加载数据并将其转化为 Spark DataFrame 格局。Spark DataFrame 是一个分布式数据集,它供给了丰厚的数据处理功用。
2. 数据预处理:对数据进行预处理,包含缺失值处理、数据转化、特征工程等。Spark MLlib 供给了多种数据预处理东西,如特征缩放、特征哈希、PCA 等。
3. 模型练习:挑选适宜的机器学习算法,并运用 Spark MLlib 供给的 API 来练习模型。例如,能够运用 Spark MLlib 的 `LinearRegression` 类来练习线性回归模型。
4. 模型评价:运用 Spark MLlib 供给的评价东西来评价模型的功用。例如,能够运用 `MulticlassClassificationEvaluator` 类来评价分类模型的功用。
5. 模型布置:将练习好的模型布置到出产环境中,以便对新数据进行猜测。Spark MLlib 供给了多种模型布置东西,如 `MLPipeline` 类和 `MLReader` 类。
6. 参数调优:经过调整模型的参数来优化模型的功用。Spark MLlib 供给了多种参数调优东西,如网格查找和随机查找。
7. 特征重要性:运用 Spark MLlib 供给的东西来剖析特征的重要性。例如,能够运用 `FeatureImportance` 类来剖析决策树模型中特征的重要性。
运用 Spark 进行机器学习具有许多长处,如分布式核算、丰厚的机器学习算法、强壮的数据处理功用等。它也有一些应战,如学习曲线峻峭、调试困难等。但总的来说,Spark 是一个强壮的东西,能够协助数据科学家和机器学习工程师构建和布置大规模的机器学习模型。
Apache Spark机器学习:高效处理大规模数据的利器
Apache Spark, 机器学习, 大数据处理, MLlib, 数据科学
跟着大数据年代的到来,怎么高效处理和剖析海量数据成为了数据科学范畴的重要课题。Apache Spark作为一种高功用的大数据处理结构,凭仗其强壮的内存核算才能和丰厚的API,成为了处理大规模数据的首选东西。本文将介绍Apache Spark机器学习模块MLlib,讨论其在数据科学中的使用。
Apache Spark简介
Apache Spark是一个开源的分布式核算体系,由加州大学伯克利分校的AMPLab开发。它供给了快速的内存核算才能,能够高效处理大规模数据集。Spark支撑多种编程言语,包含Java、Scala、Python和R,使得开发者能够依据自己的偏好挑选开发言语。
Spark机器学习模块MLlib
MLlib是Apache Spark的机器学习库,供给了多种机器学习算法,包含分类、回归、聚类、协同过滤等。MLlib的规划方针是供给简略易用的API,使得开发者能够轻松地将机器学习算法使用于大规模数据集。
MLlib的主要功用
以下是MLlib的一些主要功用:
分类:支撑多种分类算法,如逻辑回归、决策树、随机森林等。
回归:供给线性回归、岭回归、Lasso回归等算法。
聚类:支撑K-means、层次聚类、DBSCAN等聚类算法。
协同过滤:供给根据内存的协同过滤算法。
降维:支撑PCA、LDA等降维算法。
Spark机器学习使用事例
引荐体系:使用Spark MLlib中的协同过滤算法,能够构建大规模的引荐体系,为用户供给个性化的引荐。
诈骗检测:经过机器学习算法对买卖数据进行分类,能够有效地辨认和防备诈骗行为。
客户细分:使用聚类算法对客户进行细分,有助于企业更好地了解客户需求,拟定针对性的营销战略。
反常检测:经过机器学习算法对数据进行剖析,能够及时发现反常情况,进步数据安全性。
Spark机器学习的优势
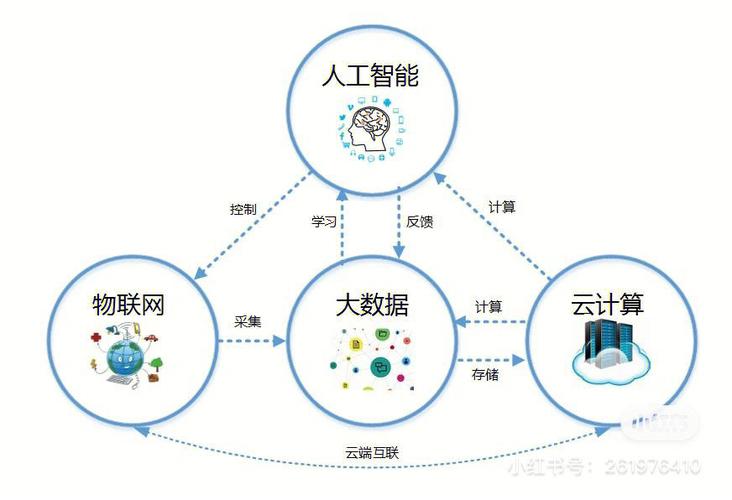
与传统的机器学习结构比较,Spark机器学习具有以下优势:
高功用:Spark的内存核算才能使得机器学习算法在处理大规模数据时具有更高的功率。
易用性:MLlib供给了丰厚的API,使得开发者能够轻松地将机器学习算法使用于实践场景。
可扩展性:Spark支撑分布式核算,能够轻松扩展到多台机器,处理更大的数据集。
与其他Spark组件的集成:Spark机器学习能够与其他Spark组件(如Spark SQL、Spark Streaming)无缝集成,完成更杂乱的数据处理和剖析使命。
Apache Spark机器学习模块MLlib为数据科学家供给了一个高效、易用的渠道,用于处理大规模数据集。经过MLlib,开发者能够轻松地将机器学习算法使用于实践场景,处理各种数据科学问题。跟着大数据年代的不断发展,Spark机器学习将在数据科学范畴发挥越来越重要的效果。
Apache Spark, 机器学习, 大数据处理, MLlib, 数据科学
相关
-
儿童学习编程机器,敞开未来智能之门详细阅读

1.玛塔编程机器人适宜年纪:49岁特色:无屏幕什物编程,适宜低龄儿童,萌萌的小塔机器人,能够培育孩子的编程爱好和逻辑思想。2.大疆机甲大师适宜年纪:5岁以上特色...
2024-12-23 0
-
AI炒股,技能革新与出资新趋势详细阅读

AI炒股,即使用人工智能技能进行股票买卖。这种买卖方法首要依赖于机器学习算法,经过剖析很多的历史数据,猜测股票的未来走势,然后进行生意操作。以下是AI炒股的一些要害点:1.数...
2024-12-23 0
-
机器学习服务,助力企业智能化转型详细阅读

机器学习服务(MachineLearningasaService,MLaaS)是一种依据云核算的服务形式,它答运用户经过互联网拜访机器学习模型和算法,而无需自行搭建和...
2024-12-23 0
-
久久归纳AI人工换脸,揭秘其原理与使用详细阅读

久久归纳AI人工换脸技能首要使用先进的AI技能完结人脸替换,下面是一些相关的详细信息和使用:1.技能原理:AI换脸技能,也称为“深度假造”(Deepfake),是经过深...
2024-12-23 0
-
ai画布巨细怎么改,AI画布巨细调整攻略详细阅读

1.AdobePhotoshop:翻开文件后,点击菜单栏的“图画”。挑选“画布巨细”。在弹出的对话框中,你能够输入新的画布宽度、高度和分辨率。...
2024-12-23 0
-
ai构成归纳实践,探究智能年代的无限或许详细阅读

1.智能制作:使用AI技能完成出产线的自动化、智能化,进步出产功率和产品质量。例如,使用机器视觉技能进行产品质量检测,使用机器人技能完成自动化安装等。2.才智城市:使用AI...
2024-12-23 0
-
机器学习试验,从数据预处理到模型评价的完好流程详细阅读

机器学习试验一般触及以下几个进程:1.数据搜集:首要需求搜集与试验相关的数据。这可所以从揭露数据集、在线资源或经过试验搜集的数据。数据的质量和数量关于试验的成功至关重要。2....
2024-12-23 0
-
机器学习 办法,原理、使用与应战详细阅读
机器学习是人工智能的一个分支,它使核算机体系能够经过数据学习并改善其功能,而无需清晰编程。机器学习办法大致能够分为以下几类:4.强化学习(ReinforcementLear...
2024-12-23 0
-
AI全站归纳模板,打造高效查找引擎优化战略详细阅读

3.AI东西箱简介:专为网文作者规划的一站式AI创造渠道,供给多个AI辅佐写作功用,如提炼热榜、AI智能拆书、卡文创意启示等。4.AI之旅AI导航...
2024-12-23 0
-
热情归纳色ai,热情与归纳色的磕碰详细阅读

1.艺术范畴:热情归纳色在艺术范畴中的运用十分广泛。艺术家经过绘画、音乐、舞蹈等艺术形式,表达对日子的深刻理解和热情。例如,现代抽象画经过颜色与形状的自由组合激起观众的...
2024-12-23 0