
机器学习瓶颈,应战与打破之路
1. 数据量缺乏:机器学习模型一般需求很多的数据来练习,以便学习数据中的形式和规则。假如数据量缺乏,模型或许无法有用地学习到有用的信息,导致功能欠安。
2. 数据质量差:数据质量对机器学习模型的功能至关重要。假如数据存在过错、缺失值或异常值,或许会影响模型的练习和猜测成果。
3. 模型杂乱度:跟着模型杂乱度的添加,练习时刻、核算资源和内存需求也会添加。在某些情况下,过杂乱的模型或许会导致过拟合,即模型在练习数据上体现杰出,但在新的、未见过的数据上体现欠安。
4. 核算资源约束:机器学习模型的练习和猜测一般需求很多的核算资源,如CPU、GPU和内存。假如核算资源有限,或许会约束模型的练习速度和功能。
5. 特征工程:特征工程是指从原始数据中提取有用特征的进程。假如特征工程做得欠好,或许会影响模型的功能。
6. 模型解说性:在某些运用场景中,模型的解说性很重要。假如模型难以解说,或许会影响用户对模型的信赖和承受度。
7. 模型泛化才能:模型泛化才能是指模型在新的、未见过的数据上体现杰出的才能。假如模型泛化才能差,或许会影响模型的实践运用效果。
8. 实时性要求:在某些运用场景中,实时性要求很高。假如模型无法满意实时性要求,或许会影响运用的效果。
9. 模型更新和维护:跟着数据的改变和模型的迭代,模型需求不断更新和维护。假如模型更新和维护本钱高,或许会影响模型的继续运用。
10. 法令和道德问题:机器学习模型的运用或许会触及法令和道德问题,如隐私维护、公平性和成见等。假如这些问题处理不妥,或许会影响模型的实践运用。
为了战胜这些瓶颈,能够采纳以下办法:
1. 搜集更多高质量的数据。2. 优化特征工程进程。3. 挑选适宜的模型和参数。4. 运用分布式核算和并行核算技能。5. 增强模型的可解说性。6. 进步模型的泛化才能。7. 优化模型更新和维护流程。8. 恪守相关法令和道德标准。
经过不断优化和改善,能够逐渐战胜机器学习瓶颈,进步模型的功能和运用效果。
机器学习瓶颈解析:应战与打破之路
一、数据瓶颈
数据是机器学习的柱石,高质量的数据获取却是一个巨大的应战。以下是数据瓶颈的几个方面:
数据稀缺:某些范畴的数据量有限,难以满意机器学习模型的需求。
数据质量:数据中或许存在噪声、缺失值、不一致等问题,影响模型的练习效果。
数据隐私:在处理敏感数据时,需求考虑数据隐私维护问题。
二、核算瓶颈
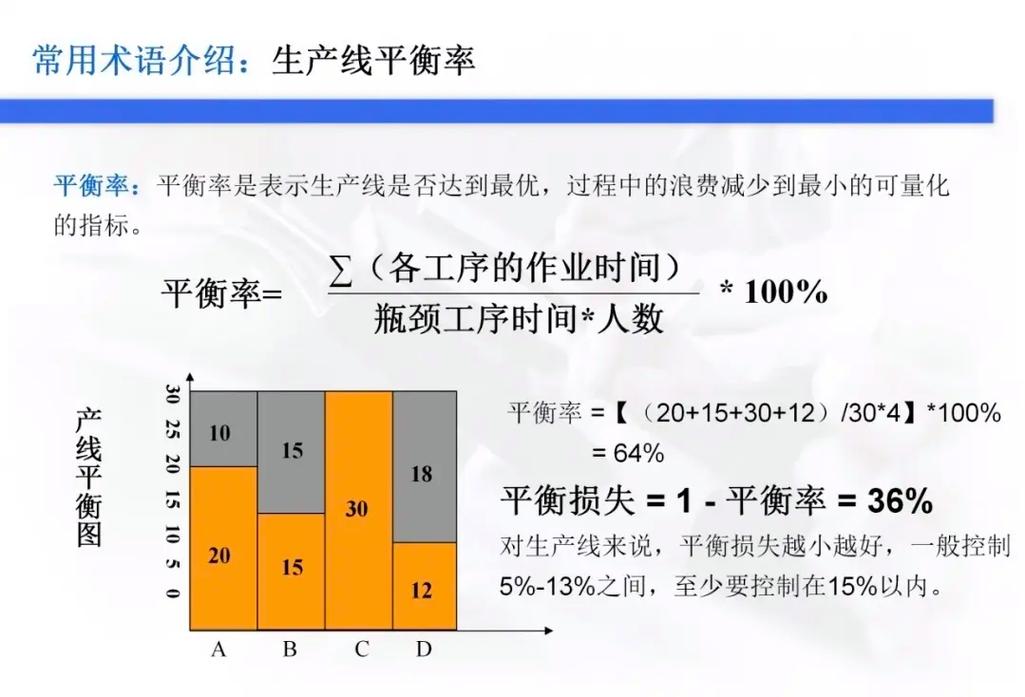
跟着模型杂乱度的进步,核算资源的需求也随之添加。以下是核算瓶颈的几个方面:
核算才能:高功能核算资源缺乏,难以满意大规模模型练习的需求。
存储空间:海量数据存储和拜访成为难题。
能耗:核算资源耗费巨大,对环境形成压力。
三、算法瓶颈

算法是机器学习的要害,在算法层面也存在一些瓶颈:
过拟合:模型在练习数据上体现杰出,但在测试数据上体现欠安。
欠拟合:模型在练习数据上体现欠安,无法捕捉数据中的有用信息。
可解说性:深度学习等杂乱模型的可解说性较差,难以了解模型的决议计划进程。
四、打破途径

数据增强:经过数据增强技能,进步数据质量和数量。
分布式核算:使用分布式核算资源,进步核算功率。
算法优化:改善算法,进步模型功能和可解说性。
跨学科研讨:结合统计学、心理学、生物学等范畴的常识,推进机器学习的开展。
机器学习在开展进程中面临着许多瓶颈,但经过不断探究和打破,咱们有理由信任,机器学习将会在各个范畴发挥更大的效果。未来,咱们需求重视数据、核算、算法等方面的瓶颈问题,并寻求有用的解决方案,以推进机器学习技能的继续开展。
相关
-
ai技能是什么技能,什么是AI技能?详细阅读

什么是AI技能?AI技能,即人工智能技能,是指经过模仿、延伸和扩展人的智能,使核算机具有学习、推理、了解、感知、认知和决议计划等才能的一系列技能。它涵盖了核算机科学、认知科学、...
2024-12-23 0
-
机器学习分类图片,技能概述详细阅读

1.卷积神经网络(CNN):这是最常用的图画分类办法之一。CNN是一种深度学习算法,它能够主动学习图画中的特征,并经过这些特征来对图画进行分类。CNN在许多图画分类使命中体现...
2024-12-23 0
-
ai智能机器人外呼体系,企业服务转型的得力助手详细阅读

AI智能机器人外呼体系是一种运用人工智能技能完结主动拨打电话、进行语音交互的体系。它可以模仿人类的语音和对话,与客户进行天然、流通的交流。以下是AI智能机器人外呼体系的一些主要...
2024-12-23 0
-
js 机器学习,敞开前端智能年代详细阅读

1.TensorFlow.js:这是一个由Google开发的开源库,答应开发者运用JavaScript进行机器学习模型的练习和布置。它供给了丰厚的API,支撑各种机...
2024-12-23 0
-
张志华 机器学习,机器学习的前驱与探究者详细阅读

张志华教授是北京大学数学科学学院的教授,一起也是大数据剖析与使用技术国家工程实验室机器学习中心主任。他的首要研讨方向包含机器学习、使用核算和数值核算,特别重视这些范畴的交叉学科...
2024-12-23 0
-
ai文件用什么翻开,AI文件用什么翻开?全面解析AI文件翻开办法详细阅读

AI文件一般指的是AdobeIllustrator文件,这是一种由Adobe公司开发的矢量图形修正软件所运用的文件格局。要翻开AI文件,你能够运用以下几种办法:1.Adob...
2024-12-23 1
-
机器学习答案,基础常识与常见算法详细阅读

机器学习答案解析:基础常识与常见算法一、机器学习概述机器学习是一种使计算机体系可以从数据中学习并做出决议计划或猜测的技能。它经过算法剖析数据,从中提取形式和常识,然后完成自动化...
2024-12-23 1
-
ai运动归纳体,AI赋能运动归纳体,打造才智健身新体会详细阅读

AI运动归纳体是一种交融了人工智能技能的体育场馆或设备,旨在经过智能化的手法提高运动体会和功率。以下是关于AI运动归纳体的详细信息:1.智能化设备和技能:Smarts...
2024-12-23 1
-
ai归纳规划试题,探究人工智能在构思规划中的运用详细阅读

AI规划挑战赛试题1.iCAN大赛简介:iCAN大赛是一个鼓舞原始立异的赛事,涵盖了人工智能、自动化、电子信息等多个范畴。赛题方向:本次AI大赛选用“机器视...
2024-12-23 0
-
在线机器学习,实时数据处理的未来趋势详细阅读

在线机器学习(OnlineMachineLearning)是一种机器学习范式,它答应模型在数据流中接连地学习并更新其参数。与传统的批量学习(BatchLearning)不...
2024-12-23 1