最近娱乐圈可是炸开了锅!咱们都知道的“雨神”周杰伦,竟然被爆出了一段老婆昆凌的视频!这消息一出,网友们纷纷炸开了锅,好奇心爆棚,都想一睹昆凌的风采。那么,这段视频到底有多火?怎么下载?今天,就让我带你一探究竟!一、雨神老婆视...
-
 娱乐新闻
娱乐新闻
雨神爆料老婆视频播放下载
 admin
2025-12-06
64 0
admin
2025-12-06
64 0 -
 最新爆料
最新爆料
网友爆料南京包子视频,一笼包子背后的故事
最近在网络上可是掀起了一阵热议呢!说的是南京包子,这可是咱们中国美食的一大亮点。这不,一位网友竟然上传了一段南京包子的视频,瞬间吸引了无数吃货的目光。接下来,就让我带你一起走进这个视频,感受一下南京包子的魅力吧!一、包子界的...
admin
2025-12-06
45 0 -
 吃瓜热榜
吃瓜热榜
全球新闻热点爆料最新,最新热点事件深度解析
你知道吗?最近全球的新闻热点可是热闹非凡,各种爆料层出不穷,让人目不暇接。今天,我就来给你揭秘一下这些让人津津乐道的新闻,让你一饱眼福!1. 环球科技突破:量子计算机的曙光最近,全球科技界都在关注一个重大突破——量子计算机的...
admin
2025-12-04
47 0 -
 吃瓜热榜
吃瓜热榜
火箭足球队爆料新闻视频,揭秘幕后新闻视频背后的真相
你知道吗?最近网上可是炸开了锅,因为火箭足球队的独家爆料新闻视频火了!这不,我就迫不及待地来和你聊聊这个话题,让你一探究竟。一、视频内容揭秘这个视频可是相当劲爆,里面曝光了火箭足球队的内部训练情况、球员们的日常生活,还有教练...
admin
2025-12-04
49 0 -
 最新爆料
最新爆料
g客在线观看,解锁精彩影视世界的便捷之门
你有没有想过,在忙碌的生活中,偶尔来点轻松的娱乐时光是多么美妙的事情?今天,就让我带你走进一个充满欢笑和惊喜的世界——g客在线观看。没错,就是那个让你笑到肚子疼,又忍不住分享给朋友的搞笑视频网站。接下来,就让我带你全方位地探...
admin
2025-12-04
47 0 -
 娱乐新闻
娱乐新闻
最新娱乐爆料事件视频播放,视频播放揭示惊人真相!
你知道吗?最近娱乐圈可是热闹非凡,有一件超级劲爆的爆料事件,简直让人停不下来!这不,我刚刚刷完视频,简直被里面的内容惊呆了!现在就让我来给你详细说说这个最新娱乐爆料事件,保证让你大呼过瘾!事件背景:揭秘明星私生活这个爆料事件...
admin
2025-12-04
47 0 -
 娱乐头条
娱乐头条
汇亚瓷砖抖音爆料视频,新品瓷砖惊艳亮相,引领家居潮流新风尚
最近抖音上可是热闹非凡呢!一款名为汇亚瓷砖的产品,因为一段爆料视频,瞬间成为了网友们热议的焦点。这不,我就来给你详细扒一扒这段视频背后的故事,让你一探究竟!瓷砖界的“网红”诞生那天,我正刷着抖音,突然一个视频吸引了我的眼球。...
admin
2025-12-04
47 0 -
 网红明星
网红明星
吃瓜搞笑小说番茄免费阅读,笑料百出,瓜田里的欢乐时光
你知道吗?最近网上有个特别搞笑的小说,简直让人笑到肚子疼,而且还是免费的哦!这不,我就迫不及待地来和你分享一下这个“吃瓜搞笑小说”的魅力了。一、番茄免费阅读,开启欢乐之旅说起这个“吃瓜搞笑小说”,它最大的亮点就是可以在番茄免...
admin
2025-12-04
67 0 -
 热门大瓜
热门大瓜
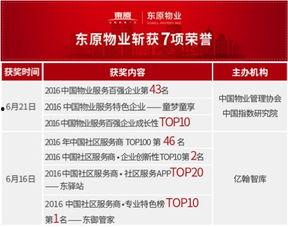
东原物业爆料最新消息,揭秘小区动态与重要通知
最近东原物业可是闹得沸沸扬扬的,这不,又有最新消息爆出来了!你听说了吗?我这就给你细细道来,让你一探究竟。东原物业风波再起话说这东原物业,一直以来都是小区居民心中的“老大难”。这不,最近又有业主在网络上爆料,说东原物业的管理...
admin
2025-12-04
47 0 -
 吃瓜热榜
吃瓜热榜
王者爆料阿狸怎么玩视频,阿狸玩法揭秘,视频教学助你轻松上分
最近在王者峡谷里,是不是也被那个可爱的小狐狸——阿狸给迷住了?她的妖娆身姿,还有那让人心跳加速的技能,简直让人欲罢不能。今天,就让我来给你详细揭秘如何玩转这位美丽的狐狸精,让你在游戏中大放异彩!阿狸的技能解析首先,我们来了解...
admin
2025-12-04
68 0
